On this page

GreptimeDB has formally unveiled the Cluster's Region Failover experiment feature in its version v0.3.2. This article delves into the implementation of this feature within the framework of GreptimeDB.
Introduction
A Region, which forms the fundamental unit for data read and write operations within a GreptimeDB cluster, plays a pivotal role in distributed read and write processes as all such operations are split by Region. The availability of a Region directly impacts the overall availability of the entire cluster. Regions are stored on Datanodes and a Region becomes unavailable when a Datanode fails to respond to requests due to hardware or network issues.
For a comprehensive introduction to the cluster architecture of GreptimeDB and definitions of terms such as Datanode, Metasrv, and Frontend nodes, please refer to this article Architecture Overview.
Introduced in version v0.3.2 of GreptimeDB, the Region Failover experiment feature was designed to address the issue of Region unavailability due to Datanode failure. At the core of this feature is the concept of letting the Metasrv serve as the cluster's "brain", determining the distribution of Regions on the Datanode, and allowing the entire cluster to recover and become operational again after a failure.
Therefore, Metasrv needs to address the following three major problems:
- Detecting a Datanode failure;
- Redistributing the Regions on the Datanode post-failure;
- Ensuring the accuracy of the Region distribution. We will delve into each of these challenges in the following sections.
Heartbeat & FailureDetector
"Heartbeat" is the starting point of our fault detection process. Each Datanode in the cluster maintains a gRPC bidirectional stream with Metasrv to function as a heartbeat connection:
ProtoBuf
service Heartbeat {
rpc Heartbeat(stream HeartbeatRequest) returns (stream HeartbeatResponse) {}
}At predetermined intervals, typically every 5 seconds by default, each Datanode sends a heartbeat request to Metasrv containing details about the active Regions on its node. This mechanism enables Metasrv to have an up-to-date overview of the distribution of all Regions across the Datanode nodes within the cluster.
Upon receiving each piece of Region information, Metasrv initiates a FailureDetector. This detector assesses the Region's status every second to ascertain its availability. This evaluation relies on calculations made from the historical frequency of the Region's heartbeats. In this process, we utilize the extensively applied "The φ accrual failure detector" algorithm, which is expertly designed to adapt to the pattern of heartbeat intervals. Under the current default settings, if two heartbeat intervals elapse without the FailureDetector receiving a heartbeat from a Region, that Region is determined to be unavailable, and it consequently proceeds into the Failover execution stage.
Failover
The successful execution of Failover crucially depends on maintaining the integrity of the process. Given the constraint that Failover cannot be executed concurrently, our approach involves receiving heartbeats and initiating the FailureDetector specifically on the leader node of Metasrv. In addition, the execution process must remain uninterrupted, even in the event of a re-election of the Metasrv leader. To address this, we employ a "procedure" framework for carrying out Region Failover. To carry out the procedure in a distributed manner, a persistent location is needed to save and restore the overall state. We've selected etcd to serve this particular purpose.
The state transition steps for executing the entire Region Failover Procedure are as follows:
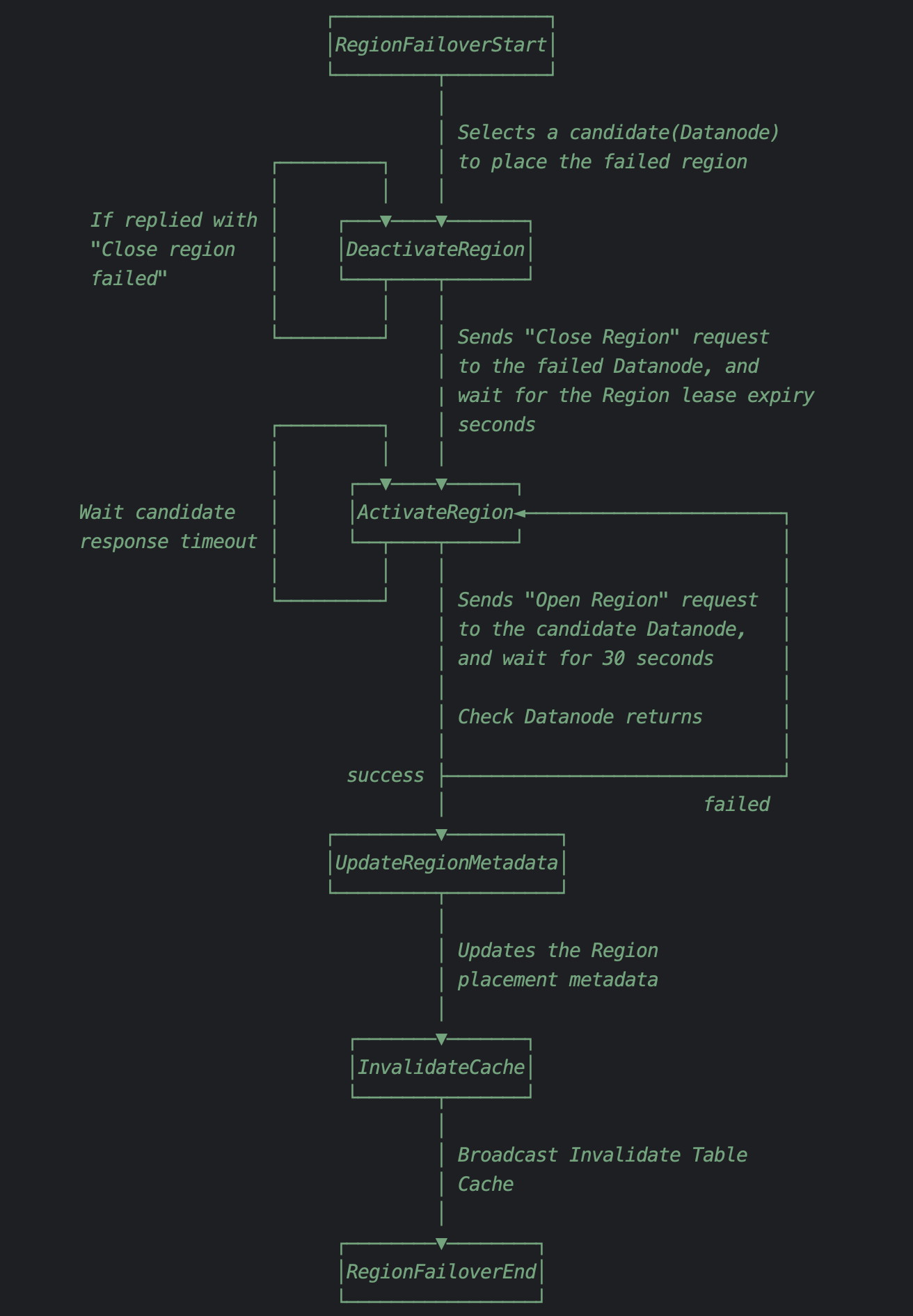
The general strategy is quite clear-cut: the process begins with the closure of the faulty Region in its original Datanode. Once the Region Lease expires (a concept we'll delve into in the subsequent section), the Region is reactivated on a predetermined healthy Datanode. The final step involves updating the Region cache on the Frontend node. Once these procedure steps are successfully carried out, the Region's availability is effectively reinstated.
Lease
The assurance of the correctness of Region distribution within a Datanode fundamentally rests on the provision that a Region can only be active on a single Datanode at any given time. To facilitate this, we've implemented the concept of a "Lease". Every Region comes equipped with a Lease, permitting a Datanode to activate a Region only within the duration of its Lease time. As a result, for each Region, every Datanode employs a "Liveness Keeper". When the Lease period expires, the Liveness Keeper autonomously shuts down the expired Region.
The renewal of a Region's Lease involves the participation of Metasrv. Here is our methodology for implementing this lease renewal: At the start of the initialization of the heartbeat loop in Datanode, it notes an Instant as an "epoch". Each time the Datanode sends a heartbeat, it includes a duration_since_epoch = Instant::now() - epoch. When Metasrv renews the Lease, it simply returns this duration_since_epoch along with a fixed Lease renewal time. On receiving the heartbeat response, the Datanode can easily calculate the new countdown for the Region Liveness Keeper by adding up the returned duration_since_epochand the fixed Lease time to the previous "epoch".
Given that the Instant always increments monotonically (except for rare hardware bug), the duration_since_epoch also rises monotonically, thus preventing the countdown from reversing. This approach effectively helps in mitigating the effects of any potential clock inconsistencies between the Datanode and Metasrv within a distributed environment.
Summary
This article presents an overview of the design and execution of the Region Failover experiment feature in the v0.3.2 release of GreptimeDB. The principal elements encompass heartbeats, the FailureDetector, the protocol for carrying out Region Failover, and the concept of Region Leases. As evident, sustaining high availability within a cluster involves considerable complexity. In our forthcoming releases, we aim to introduce further enhancements to the Region Failover functionality.




