
On this page

What is KubeBlocks?
KubeBlocks is an open-source, cloud-native data infrastructure created by ApeCloud, aiming at assisting application developers and platform engineers in effectively managing databases and various analytical workloads on Kubernetes.
The name 'KubeBlocks' is derived from "Kubernetes (K8s)" and "LEGO blocks", with the intention of making data infrastructure management on K8s as efficient and enjoyable as building with LEGO blocks. KubeBlocks supports multiple cloud providers, such as AWS, Azure, Google Cloud Platform (GCP), etc, and offers a declarative, unified way to enhance DevOps efficiency.
Currently, KubeBlocks supports various types of databases including relational, NoSQL, vector, time-series, graph and stream processing systems.
Why is integration with KubeBlocks important?
Building data infrastructure on K8s has become increasingly popular. However, the most challenging obstacles in this process include difficulties integrating with various clouds, lack of reliable operators, and the steep learning curve of K8s.
KubeBlocks provides an open-source solution that not only helps application developers and platform engineers configure richer features and services for data infrastructure but also assists non-K8s professionals in rapidly building full-stack, production-ready data infrastructure.
By integrating with KubeBlocks, GreptimeDB gains a more convenient and efficient cluster deployment method. Additionally, our users can enjoy powerful cluster management capabilities such as scaling, monitoring, backup and recovery provided by KubeBlocks. So why not take full advantage of it?
How to integrate with KubeBlocks?
KubeBlocks divides the information required for a cluster into three categories:
Topology information, which is ClusterDefinition resource object, defines the required components of the cluster and how these components are deployed.
Version information, which is ClusterVersion resource object, defines component image versions and related configuration information.
Resource information, which is Cluster resource object, defines resources such as CPU, memory, disk, and replica count.
KubeBlocks decouples the topology, version, and resource information of a cluster, making the information described by each object clearer and more focused. The combination of these objects can generate a richer cluster.
The compositional relationships between these three types of objects describing a cluster are shown in the diagram below:
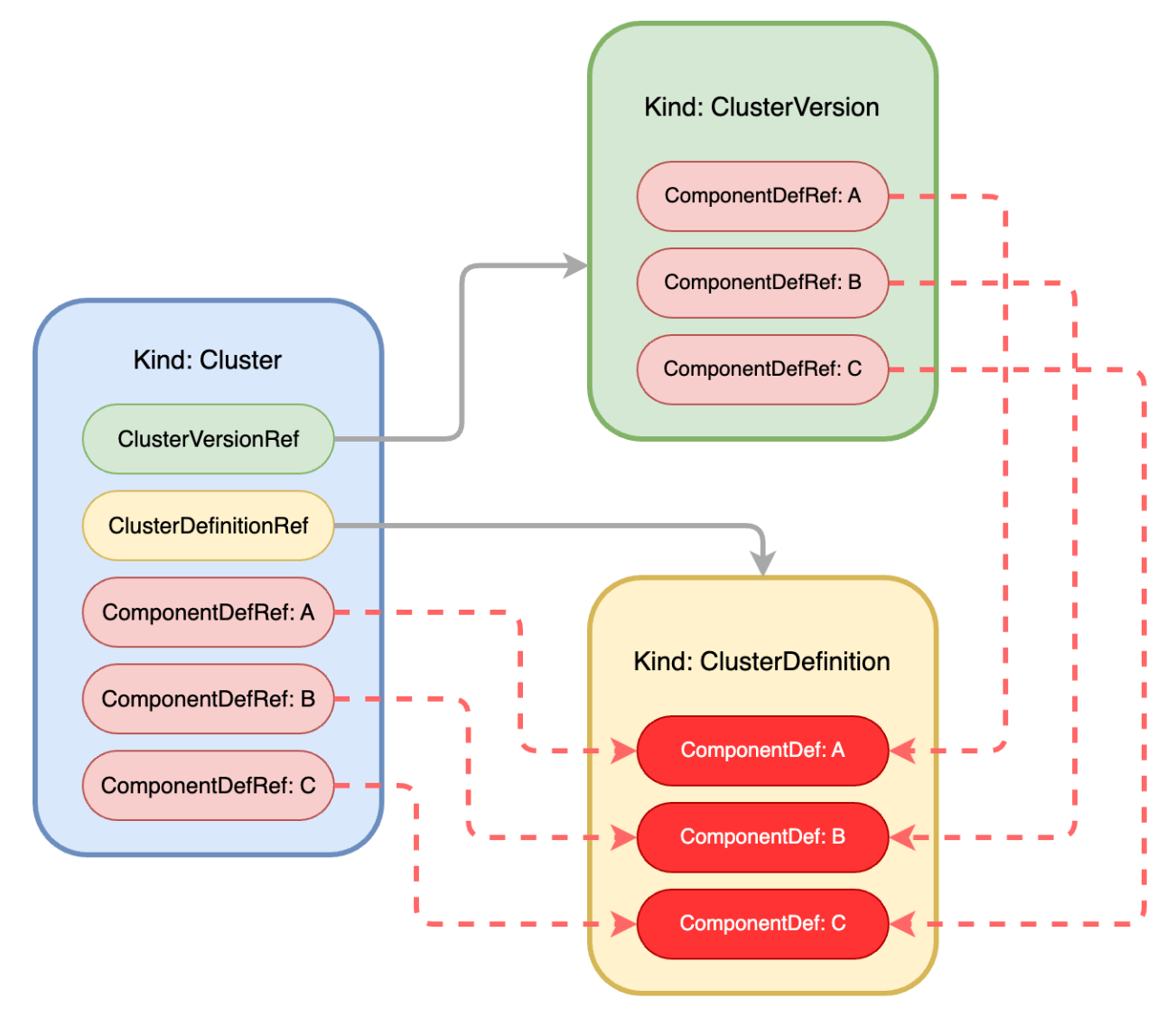
Among which, ComponentDef defines the deployment information of a component in a cluster, while ComponentDefRef describes a reference to a component's definition. In this reference, various object information related to the corresponding component can be defined (for example, in ClusterVersion's ComponentDefRef: A, the image version used by component A is defined as the "latest"; in Cluster’s ComponentDefRef: A, the replica count of component A is defined as 3, and so on).
Basically, integrating KubeBlocks is essentially declaring information that can describe the topology, version, and resources of a cluster.
The Overall Cluster Architecture of GreptimeDB
GreptimeDB cluster architecture is made of 3 components, they are meta, frontend and datanode, please see the diagram below:
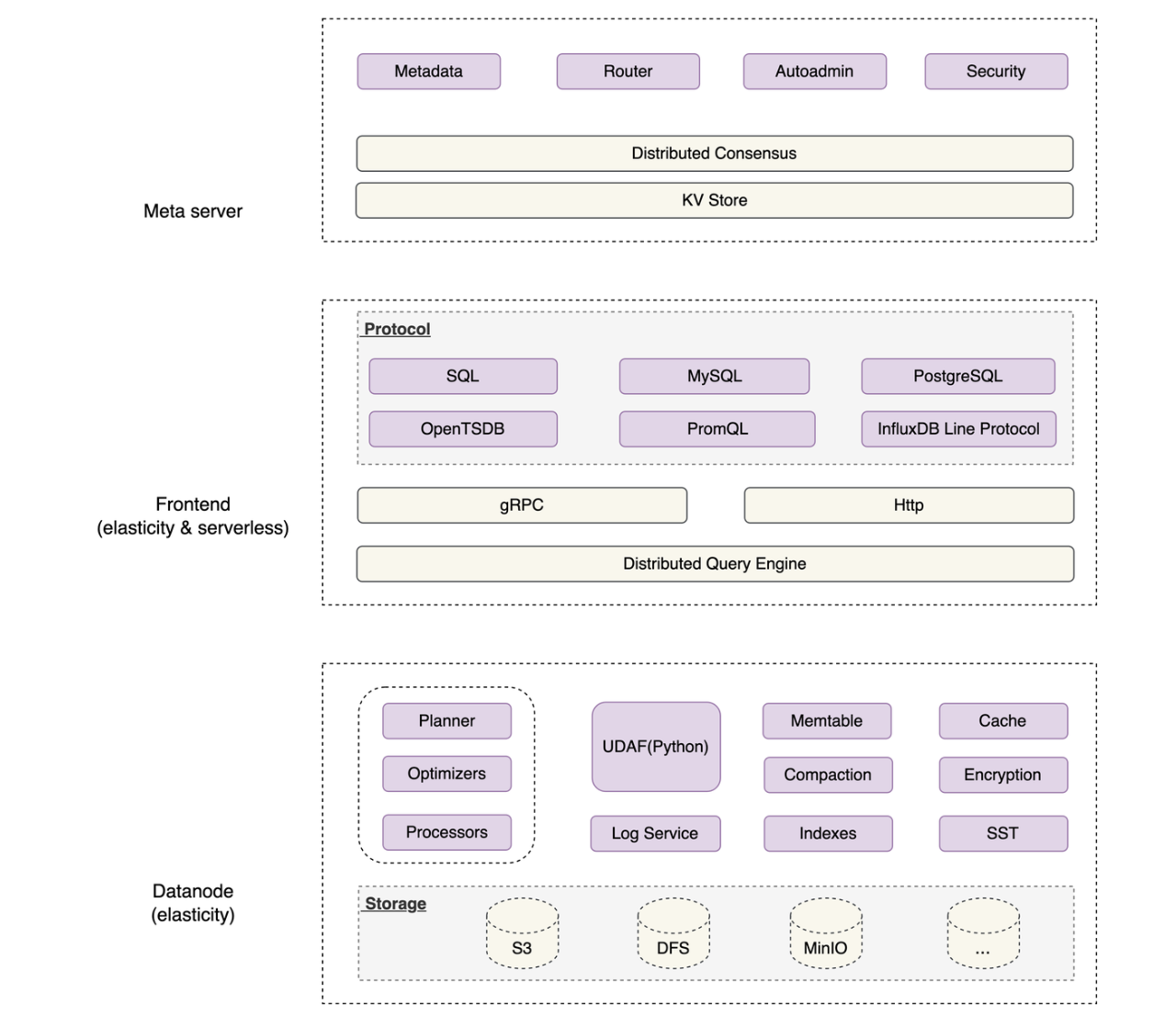
Explanations:
The frontend is responsible for exposing read and write interfaces of different protocols, forwarding requests to datanodes; it belongs to the stateless type of a component.
The
datanodeis responsible for persistently storing data; it's stateful.The
metaserver is responsible for the coordination between thefrontendanddatanode; it's stateless. In this article, we assume that the kv-store used bymetaisetcd.
Integration Experience Sharing
To learn complete integration and operational details of GreptimeDB with KubeBlocks, you can refer to the following 2 PRs:
While this article won't delve into specific configuration details, it will share insights from our integration process, in hopes that you find them beneficial.
Cross-component references
In a cluster, there may be cases where one component takes reference of another component. For example, in GreptimeDB cluster, the frontend component takes reference of the Service address of the meta server and datanode.
KubeBlocks introduces a componentDefRef field, facilitating cross-component value references. In the configuration illustrated below, the frontend component declares a reference to the meta component which references the Service name created by the meta component. This name is subsequently stored within the GREPTIMEDB_META_SVC environment variable, making it accessible to the frontend component or other related components. For referencing purposes, anchors can be defined using & and then called upon with *.
yaml
componentDefs:
- name: frontend
componentDefRef:
- &metaRef
componentDefName: meta
componentRefEnv:
- name: GREPTIMEDB_META_SVC
valueFrom:
type: ServiceRef
# ...
containers:
- name: frontend
args:
- --metasrv-addr
- $(GREPTIMEDB_META_SVC).$(KB_NAMESPACE).svc{{ .Values.clusterDomain }}:3002
# ...
- name: datanode
componentDefRef:
- *metaRef
podSpec:
containers:
- name: datanode
args:
- --metasrv-addr
- $(GREPTIMEDB_META_SVC).$(KB_NAMESPACE).svc{{ .Values.clusterDomain }}:3002
# ...In addition to referencing Service, KubeBlocks also supports referencing Fields in the component Spec or Headless Services.
Sequential constraints of startup among multiple components
Typically, a cluster is composed of multiple components, and the start of one component may depend on the state of another component. Taking GreptimeDB cluster as an example, its four components (including etcd) need to be started in the order of: etcd -> meta -> datanode -> frontend.
When KubeBlocks deploys a cluster, it starts all components simultaneously. Since the startup of each component is unordered, if a dependent component runs after a component that depends on it, it will cause the latter's startup to fail, triggering a restart event. For instance, if etcd starts up after meta has already begun, it triggers a meta restart. Overlooking the startup sequence of components might still lead to a successful cluster deployment eventually, but it inevitably lengthens the deployment time. Additionally, each component may undergo unnecessary restarts, making the process less elegant.
Considering the Init Container function provided by K8s, in scenarios where there is a need for sequential constraints on the startup order of components, initContainers can be introduced to detect the state of dependent components. As shown in the following configuration, in conjunction with componentDefRef, the meta server will wait for the Service of etcd to be created before starting.
yaml
componentDefs:
- name: meta
componentDefRef:
- &etcdRef
componentDefName: etcd
componentRefEnv:
- name: GREPTIMEDB_ETCD_SVC
valueFrom:
type: ServiceRef
podSpec:
initContainers:
- name: wait-etcd
image: busybox:1.28
imagePullPolicy: {{default .Values.images.pullPolicy "IfNotPresent"}}
command:
- bin/sh
- -c
- |
until nslookup ${GREPTIMEDB_ETCD_SVC}-headless.${KB_NAMESPACE}.svc{{ .Values.clusterDomain }}; do
echo "waiting for etcd"; sleep 2;
done;
# ...Agile ConfigMap mounting
In the configurations of ClusterDefinition, we often unconsciously mount a ConfigMap in the containers of components:
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: greptimedb-meta
# ...
---
# ...
componentDefs:
- name: meta
podSpec:
containers:
- name: meta
volumeMounts:
- mountPath: /etc/greptimedb
name: meta-config
-
# ...
volumes:
- configMap:
name: greptimedb-meta
name: meta-configThis way of mounting only takes effect when the Cluster, ClusterDefinition, and ClusterVersion objects are located within the same namespace. If they are in different namespaces, the mounting of the ConfigMap becomes ineffective because ConfigMap is Namespaced resource object.
KubeBlocks provides a ConfigSpec Field to address the aforementioned issue. As shown in the following configuration, templateRef corresponds to the name of the referenced ConfigMap.
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: greptimedb-meta
# ...
---
# ...
componentDefs:
- name: meta
configSpecs:
- name: greptimedb-meta
templateRef: greptimedb-meta
volumeName: meta-config
namespace: {{ .Release.Namespace }}
podSpec:
containers:
- name: meta
volumeMounts:
- mountPath: /etc/greptimedb
name: meta-config
# ...Summary
This article shares some experiences of integrating GreptimeDB with KubeBlocks. We present real issues encountered during the integration process and their solutions.
Currently, GreptimeDB has only integrated the deployment capability of KubeBlocks, and there are many rich features that have not been integrated yet. The goal is to integrate more of KubeBlocks in the future, and we welcome you to join us!




