On this page

Preface
GreptimeDB supports deployment in both standalone and distributed modes, but a sharp question follows: how confident are we in this complex system that we have put into production? During the iteration from v0.3 to v0.4, we introduced Chaos Engineering to enhance the robustness of the system.
How is chaos engineering implemented?
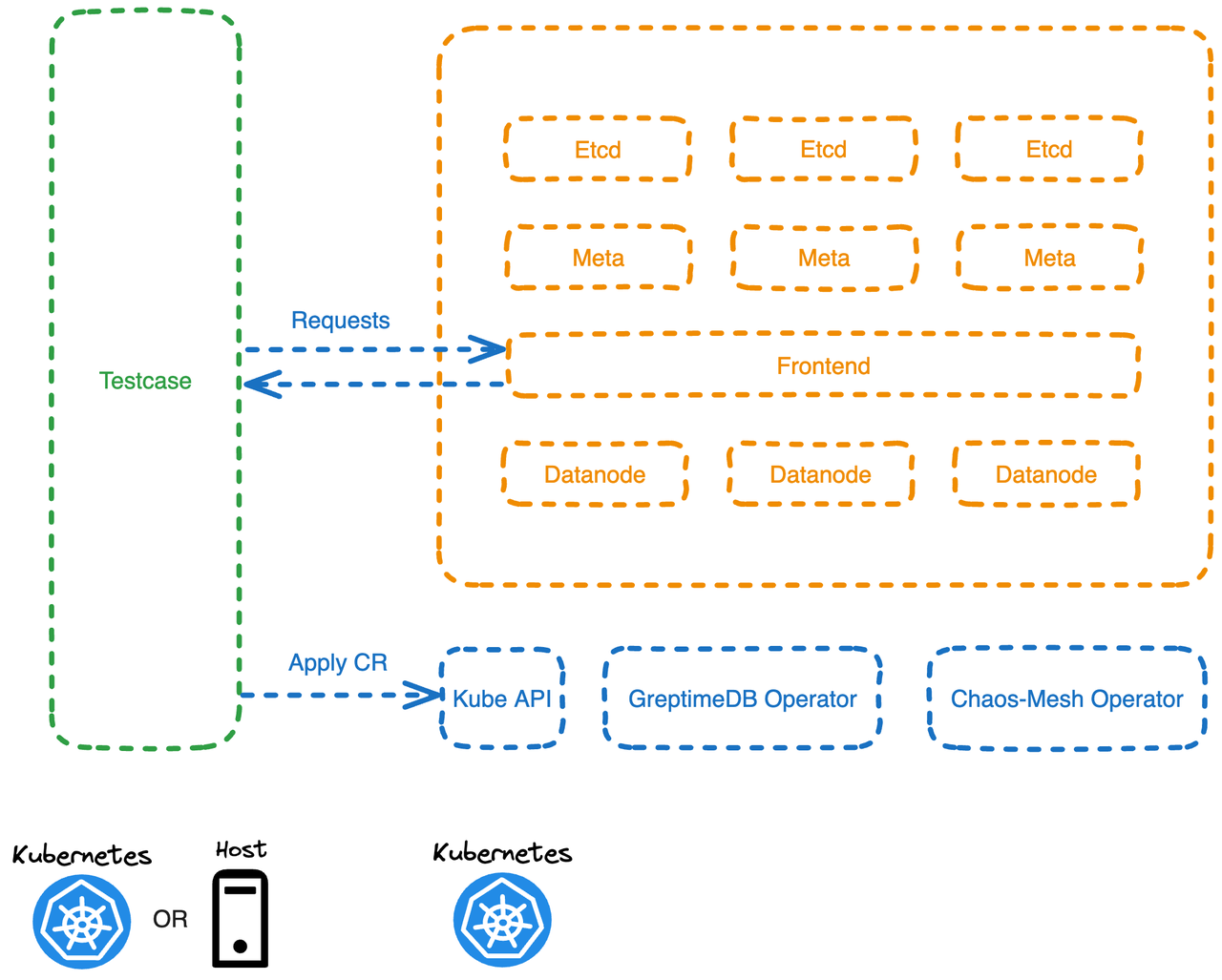
We chose Chaos Mesh as the fault injection tool and run a test program (Testcase) in the Pod, which defines a CR (Custom Resource) to inject faults into specific Pods within the DB cluster. After transferring the faults, the tool validates the availability and data integrity of the DB cluster.
Below is an example of injecting a Pod Kill fault into a Pod named greptimedb-datanode-1 in the greptimedb-cluster namespace.
yaml
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
namespace: greptimedb-cluster
spec:
action: pod-kill
mode: one
selector:
filedSelectors:
'metadata.name': 'greptimedb-datanode-1'To facilitate debugging the test program, the test program can be run directly on the host in the dev. environment and access the DB service in K8s through Kubectl's port forwarding.
Technical Knolwedge Exchanges
1. Start from the Smallest Scenario
In testing scenarios with low coverage, there might be some "two negatives make a positive" situations, making the entire system appear to be running "normally" (in fact, even with high coverage, these issues may still exist). Testing can begin with the smallest scenario, at which stage you need to have a very clear understanding of the system's expected behaviors. By examining the system logs, you can determine whether the system's behaviors really meet the expectations, so as to timely provide the system with corresponding integration tests when problems are discovered.
For instance, we need to verify whether the system can tolerate a Datanode being killed and trigger the Region Failover process (that is, migrating the Region to other available nodes). We can verify this by building a minimal scenario (a small number of tables, a small amount of data). Typically, there will be a certain time interval from when a fault is injected to when it actually occurs. At this time, we need some methods to verify whether a fault is indeed injected. We normally use 2 approaches:
- Observe through the Kube API if the number of Pod replicas in the ReplicaSet is less than expected;
- perform read and write operations on the target node.
Continuously launch small amounts of read and write operations that will be routed to the target node before observing the fault; when the client server returns a failure, it can be considered that the target node is unavailable. Afterwards, wait for the cluster to recover (for example, by calling the Kube API to wait for the ReplicaSet's Pod replica number to return to expected), then we can start verifying service availability and data integrity.
2. Create a close to real testing scenario
GreptimeDB stores data on cost-effective object storage cloud services such as AWS S3. Storage like S3, compared to local storage, actually has quite a few differences in testing, mainly reflected in the latency of accessing S3. It is essential to test as close to real scenarios as early as possible, namely testing the DB cluster using S3 storage. When developing the testing program, the data of the DB cluster being tested should also be stored in an S3 close to the dev. environment.
3. Clearly defined testing plan + Integration Test as the back-up
Before starting chaos testing, have a well-defined testing plan and make sure it covers all testing scenarios in the integration tests. Chaos testing still involves a fair amount of additional work, and having the tests well-prepared in advance can save a lot of time. Of course, chaos testing and integration testing can be said to complement each other; however it's highly possible that you will still encourter some new and surprising incidents during chaos testing, so to be mentally prepared for these surprises 🤣
4. Pay attention to small incidences
Enough being said for #3 above, any issue that occurs by chance should be thoroughly investigated afterwards, and problems that happen with a small probability actually require a large number of retries, and rely on logs for troubleshooting.
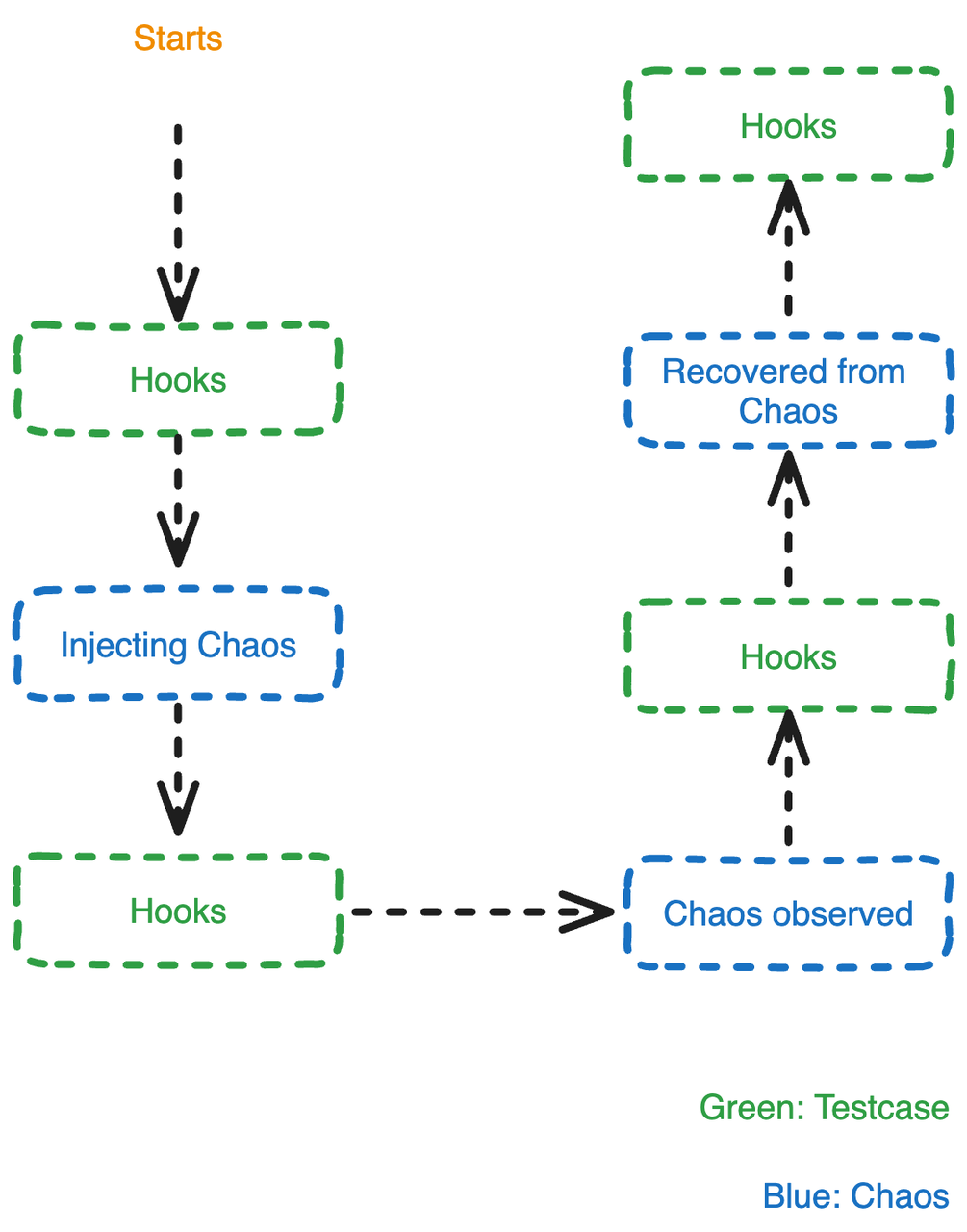
5. Building Reusable Failures
Creating a chaos test requires a considerable amount of effort from fault injection, observing the occurrence of the fault, waiting for the service to fully recover, etc. By abstracting these steps, we can test multiple different scenarios by injecting one default.
Typical Bugs During Chaos Testing
The bugs we found in chaos engineering mainly fall into the following categories:
- Inconsistent behavior due to different implementations of Traits
- Redundant fields or interfaces
- Multiple bugs that cancel each other out, resulting in an appears to be like a positive effect
- Ambiguities caused by not using aliases
- Inconsistencies between data and cache in Corner Case
- Some omissions caused by multiple people collaborating during the iteration process
We also unexpectedly discovered an bug from upstream package: OpenDAL FsBackend's asynchronous write did not call flush before sync_all, posing a potential risk of data loss. We have reported and fixed this bug, which was corrected in version 0.40. You can learn more through the link below:




