
On this page


With the rapid evolution of artificial intelligence technology, OpenAI has established itself as a frontrunner in the field. It demonstrates remarkable proficiency in a range of language processing tasks, including machine translation, text classification, and text generation. Parallel to OpenAI's ascent, many high-quality, open-source large language models such as Llama, ChatGLM, and Qwen have also gained prominence. These exceptional open-source models are invaluable assets for teams aiming to swiftly develop robust Large Language Model (LLM) applications.
With a myriad of options at hand, the challenge becomes how to uniformly use OpenAI's interface while also reducing development costs. Additionally, efficiently and continuously monitoring the performance of LLM applications is crucial, but how could we avoid increasing the complexity of development? GreptimeAI and Xinference offer pragmatic solutions to address these pivotal concerns.
What is GreptimeAI?
GreptimeAI, built upon the open-source time-series database GreptimeDB, offers an observability solution for Large Language Model (LLM) applications, currently supporting both LangChain and OpenAI's ecosystem. GreptimeAI enables you to understand cost, performance, traffic and security aspects in real-time, helping teams enhance the reliability of LLM applications.
What is Xinference?
Xorbits Inference (Xinference) is an open-source platform to streamline the operation and integration of a wide array of AI models. With Xinference, you’re empowered to run inference using any open-source LLMs, embedding models, and multimodal models either in the cloud or on your own premises, and create robust AI-driven applications. It provides a RESTful API compatible with OpenAI API, Python SDK, CLI, and WebUI. Furthermore, it integrates third-party developer tools like LangChain, LlamaIndex, and Dify, facilitating model integration and development.
Xinference supports multiple inference engines such as Transformers, vLLM, and GGML and is suitable for various hardware environments. It also supports multiple-nodes deployment, efficiently allocating model inference tasks across multiple devices or machines.
Utilize GreptimeAI + Xinference to Deploy and Monitor an LLM App
Next, we will take the Llama 2 model as an example to demonstrate how to install and run the model locally using Xinference. This example will feature the use of an OpenAI-style function call to conduct a weather query. Additionally, we will demonstrate how GreptimeAI can be effectively utilized to monitor the usage and performance of the LLM application.
Register and Get GreptimeAI Configuration Info
Visit https://console.greptime.cloud to register and create an AI service, then go to the Dashboard, click on the Setup page to get configuration information for OpenAI.
Start the Xinference Model Service
Initiating the Xinference model service locally is pretty straightforward. Simply enter the following command:
sql
xinference-local -H 0.0.0.0By default, Xinference initializes the service on your local machine, typically using port 9997. The process of installing Xinference locally is not covered here and you can refer to this article for installation instructions.
Launch the Model via Web UI
After starting Xinference, you can access its Web UI by entering http://localhost:9997 in your browser. This provides a user-friendly interface.
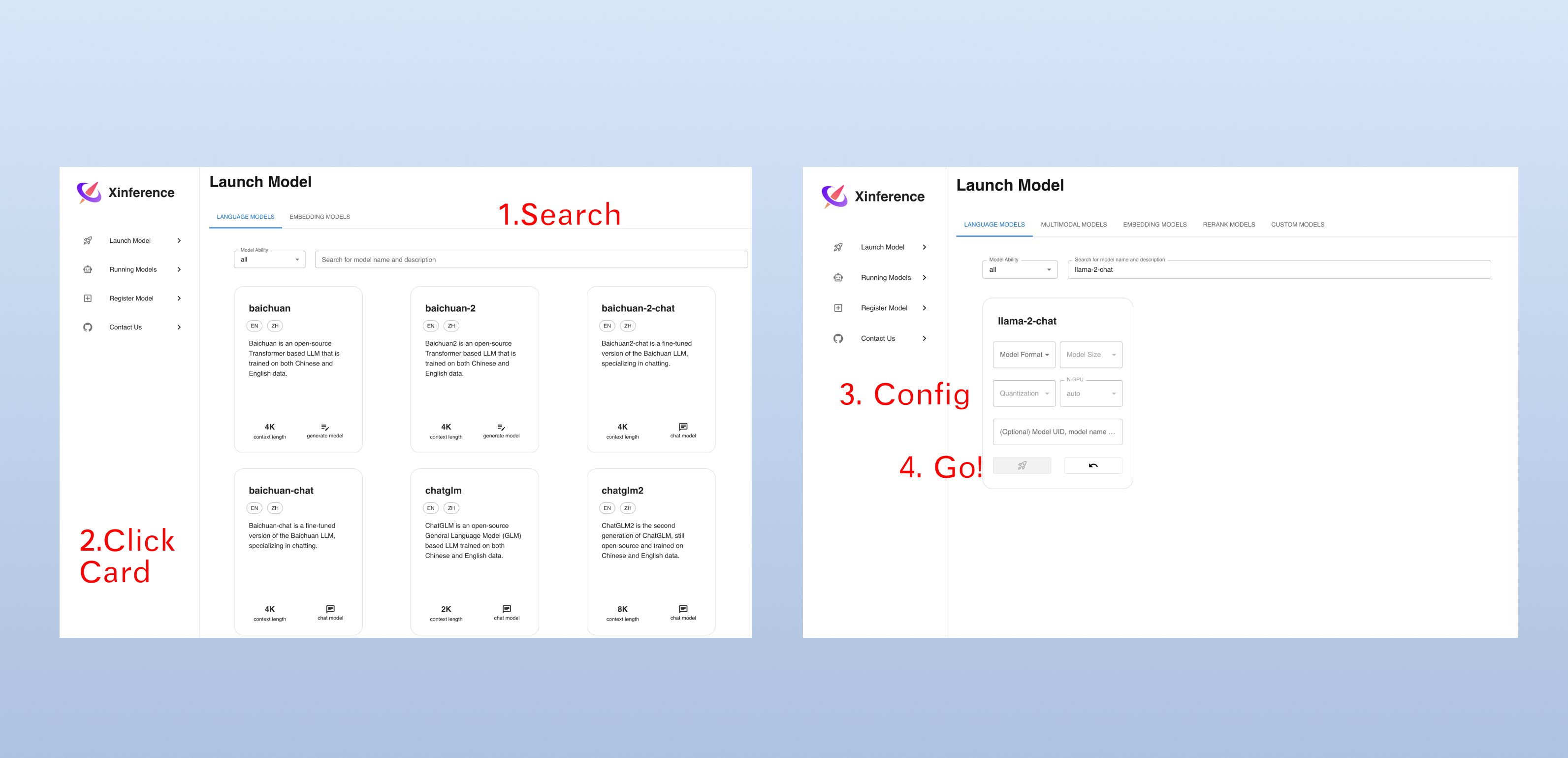
Launch the Model via Command Line Tool
Alternatively, the model can be launched using Xinference's command-line tool. The default Model UID is set to llama-2-chat, which will be used subsequently for accessing the model.
sql
xinference launch -n llama-2-chat -s 13 -f pytorchObtain Weather Information through an OpenAI-Styled Interface
Suppose we have the capability to fetch weather information for a specific city using the get_current_weather function, with parameters location and format.
Configure and Call the OpenAI Interface
Access the Xinference local service using OpenAI's Python SDK and utilize GreptimeAI for metrics and traces collection. You can create dialogues using the chat.completions module, and specify the list of functions we've defined using tools.
python
from greptimeai import openai_patcher
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:9997/v1",
)
openai_patcher.setup(client=client)
messages = [
{"role": "system", "content": "You are a helpful assistant. Do not make assumptions about the values in the function calls."},
{"role": "user", "content": "What's the weather in New York now"}
]
chat_completion = client.chat.completions.create(
model="llama-2-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print('func_name: ', chat_completion.choices[0].message.tool_calls[0].function.name)
print('func_args: ', chat_completion.choices[0].message.tool_calls[0].function.arguments)Details of the tools
The definition of the function calling tool list is as follows.
python
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "obtain current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "city, such as New York",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "the temperature unit used, determined by the specific city",
},
},
"required": ["location", "format"],
},
},
}
]The output is as follows, showing the result generated by the Llama 2 model:
python
func_name: get_current_weather
func_args: {"location": "New York", "format": "celsius"}Retrieve the Function Call Results and Making Subsequent Calls
Let's assume that we have invoked the get_current_weather function with specified parameters and obtained the results. These results, along with the context, will then be resent to the Llama 2 model:
python
messages.append(chat_completion.choices[0].message.model_dump())
messages.append({
"role": "tool",
"tool_call_id": messages[-1]["tool_calls"][0]["id"],
"name": messages[-1]["tool_calls"][0]["function"]["name"],
"content": str({"temperature": "10", "temperature_unit": "celsius"})
})
chat_completion = client.chat.completions.create(
model="llama-2-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print(chat_completion.choices[0].message.content)Final Result
The Llama 2 model ultimately generates the following response:
plain
The current temperature in New York is 10 degrees Celsius.GreptimeAI Dashboard
On the GreptimeAI Dashboard, you have the capability to comprehensively monitor LLM application behaviors based on the OpenAI interface in real-time, including key metrics such as token, cost, latency, and trace. Below is a capture of the Dashboard's overview page.
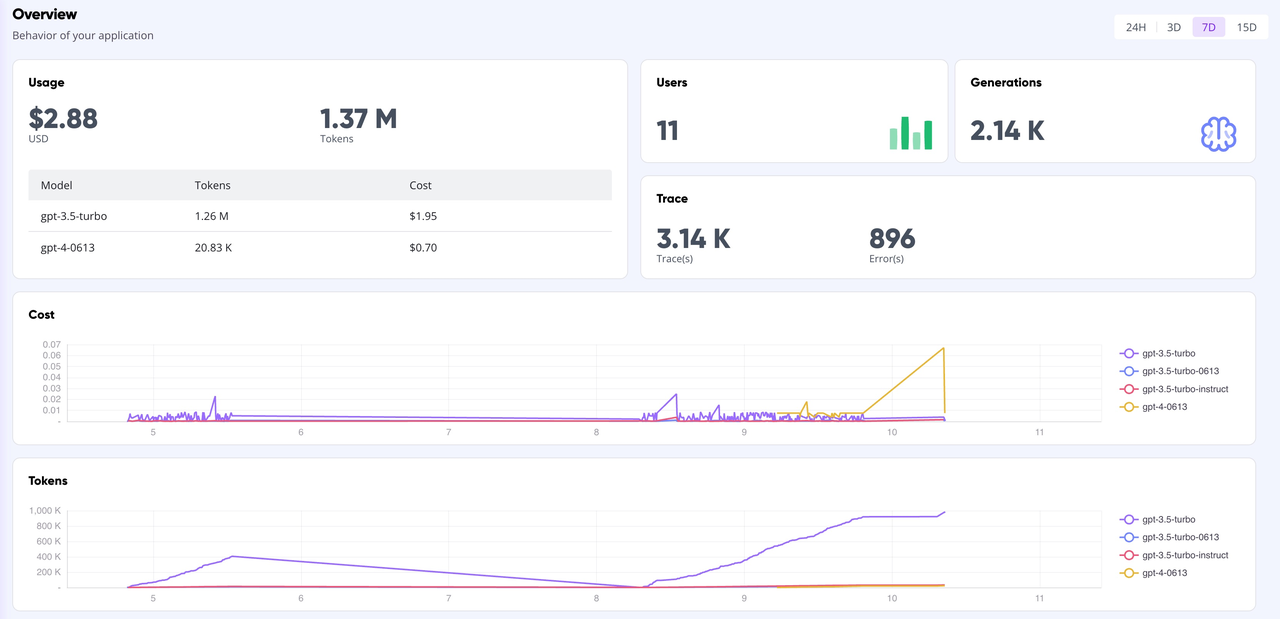
Summary
If you're developing LLM applications with open-source large language models and aspire to utilize API calls akin to OpenAI's style, then choosing Xinference for managing your inference models, coupled with GreptimeAI for performance monitoring, would be a good choice. Whether it's for complex data analysis or simple routine queries, Xinference offers robust and flexible model management capabilities. Furthermore, GreptimeAI's monitoring features help you understand and optimize your model's performance and resource usage.
We look forward to seeing what you achieve with these tools and are eager to hear about your insights and experiences using GreptimeAI and Xinference. If you experience any issues or feedback, please don't hesitate to reach out to us at [email protected] or via Slack. Together, let's delve into the vast and exciting realm of artificial intelligence!




