
On this page
Background
GreptimeDB is a distributed time-series database leveraging a shared storage architecture. Its foundational storage layer utilizes object storage, facilitating cost reductions of up to fiftyfold. Within GreptimeDB's distributed framework, it encompasses three distinct node roles: MetaSrv, Datanode, and Frontend.
MetaSrv manages the metadata of databases and tables, including the distribution of table partitions across the cluster and routing information for requests.
Datanode is responsible for storing the table partition (Region) data in cluster's shared storage and processing read and write requests sent from the Frontend.
Frontend is a stateless component that can be scaled according to demand. Its main responsibilities include receiving and authenticating requests, converting various protocols to the internal protocol of the GreptimeDB cluster, and forwarding requests to the appropriate Datanode node based on metadata.
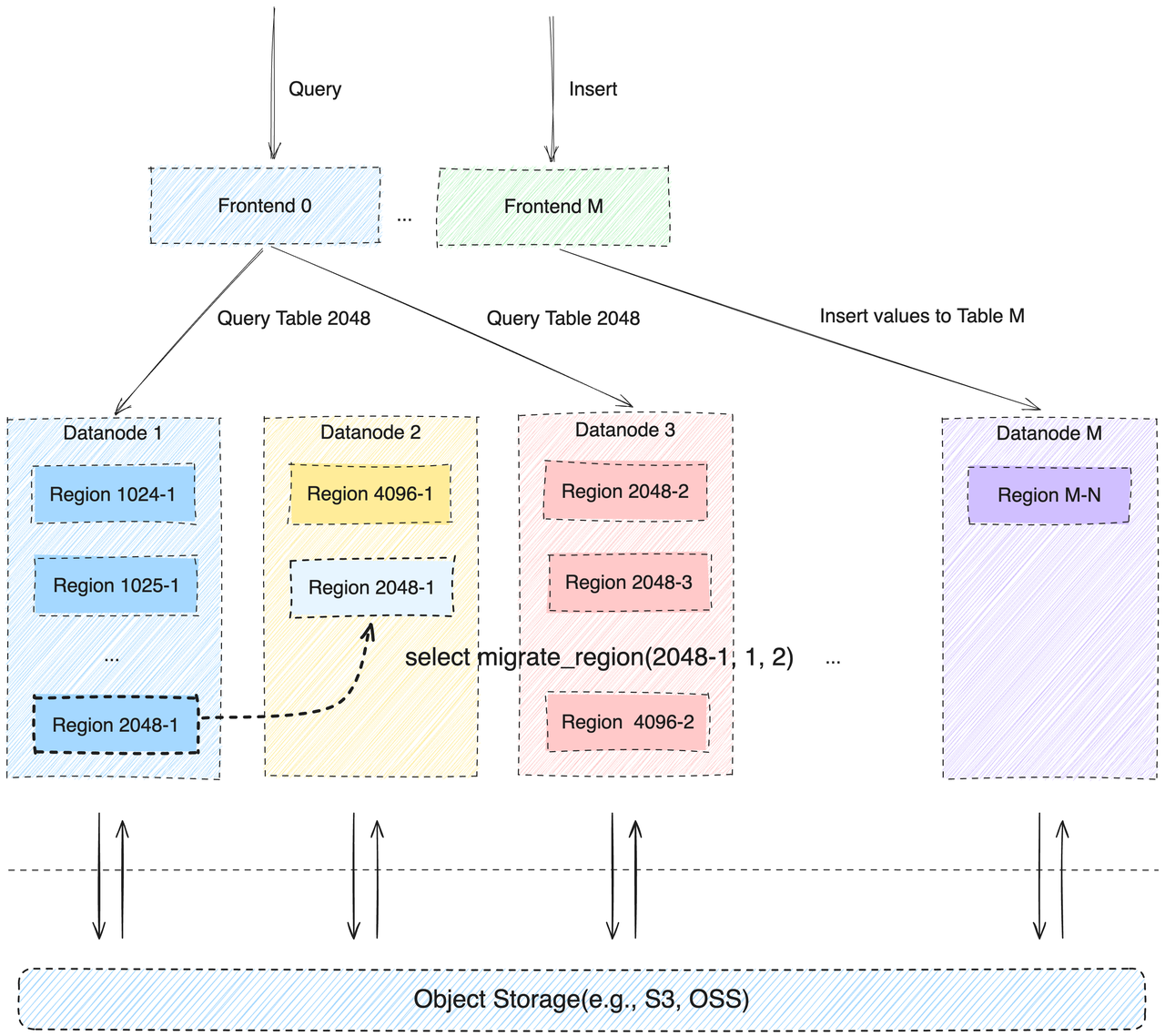
Region Migration
Starting from v0.6.0, GreptimeDB has gained the capability to migrate table partition (Region) data from one Datanode to another. GreptimeDB utilizes a shared storage architecture, where data files are stored on object storage and shared across multiple Datanodes.
Hence, Region Migration only requires the migration of a small amount of local data from the Datanode Memtable. Compared to databases employing a Shared Nothing architecture, GreptimeDB's Region Migration involves transferring a significantly smaller volume of data, resulting in reduced overall migration durations and a more seamless load-balancing experience at the higher layers.
Technical Specifics
Internal
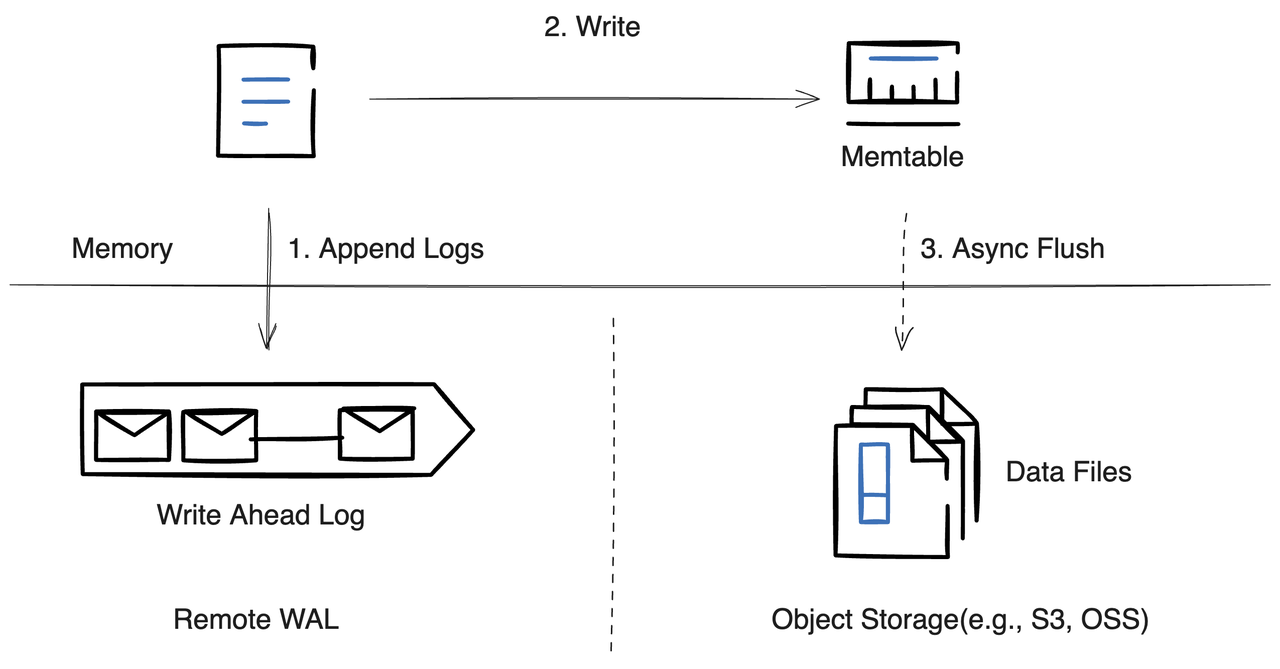
When a write request reaches a Datanode, the Datanode logs the data to the Remote WAL, then updates the Memtable before responding to the request. From this, we derive the following relationship:
The complete partition data = Partial data in Remote WAL + Data files on object storageSince the data stored on object storage is shared among Datanodes, the target Datanode for Region migration only needs to replay the WAL of the table partition (Region) starting from a specified location.
Migration Process
Users need to specify the Region ID to be migrated, the Datanode ID to which the Region ID belongs, and the target node's Datanode ID. Users can also specify a Timeout parameter for replaying data (optional).
The migration command is as follows:
sql
select migrate_region(
region_id,
from_dn_id,
to_dn_id,
[replay_timeout(s)]);You can query the distribution of Regions in a table named 'migration_target' using the following SQL command:
sql
select
b.peer_id as datanode_id,
a.greptime_partition_id as region_id
from
information_schema.partitions a left join information_schema.greptime_region_peers b
on a.greptime_partition_id = b.region_id
where a.table_name='migration_target'
order by datanode_id asc;Example of the query result: The table contains a Region with Region ID 4398046511104 located on Datanode 1.
+-------------+---------------+
| datanode_id | region_id |
+-------------+---------------+
| 1 | 4398046511104 |
+-------------+---------------+
1 row in set (0.01 sec)Preparing Candidate Partitions
When a user inputs the command to migrate a partition, the cluster's MetaSrv initiates a partition migration Procedure (read this article to learn how GreptimeDB improves the fault tolerance capability). The Procedure first checks if there is a Candidate Region that exists on the Destination Datanode. If not, it would open a Candidate Region on the target node.
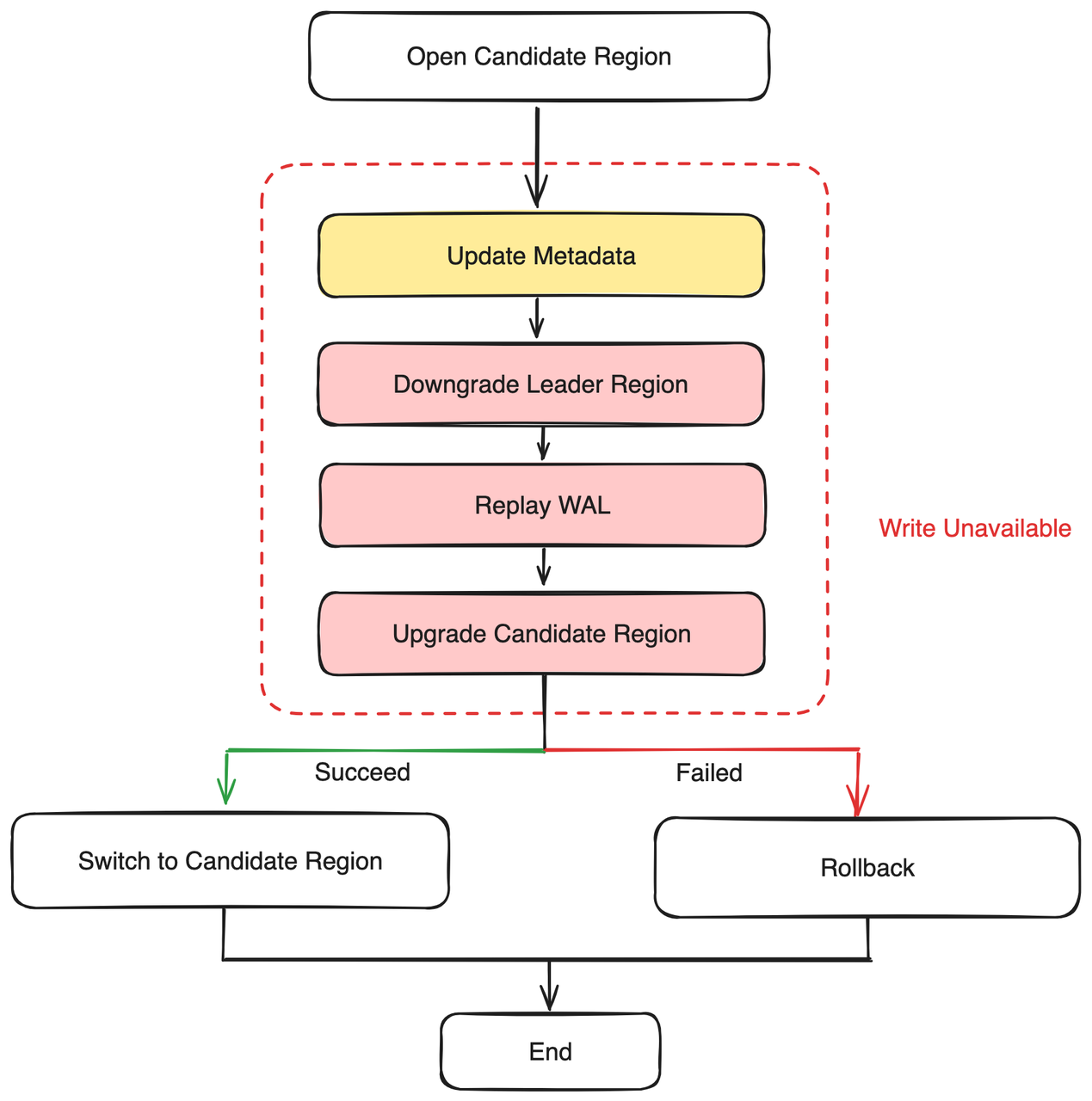
Performing Data Migration
Before the start of data migration, MetaSrv marks the original partition as degraded to cut off write traffic (corresponding to "Update Metadata" and "Downgrade Leader Region" in the diagram);
Then, MetaSrv notifies the Candidate Region to start replaying data from the Remote WAL (corresponding to "Replay WAL" and "Upgrade Candidate Region" in the diagram);
If data is successfully replayed, the Candidate node will be upgraded to the Leader of the partition (corresponding to "Switch to Candidate Region" in the diagram), and continue to accept write traffic;
Otherwise, if any non-retriable errors occur during data replay, the Procedure will remove the downgrade mark from the original partition, allowing upper-layer traffic to continue writing.
Future Plan
In the future, we plan to leverage the capabilities of Region Migration to realize hot data migration and horizontal scaling for load balancing.
Without disrupting service, our goal is to smartly allocate table partitions (Regions) based on the real-time monitorered load conditions and business demands, thereby enhancing resource efficiency. This will enable more intelligent and efficient data management, providing sustainable support for the constantly evolving business environment.
In the upcoming week, we will also post a user guide on how to how to migrate datanode table partitions. Stay tuned.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




