
On this page


As AI technology advances, GPT-4 stands out in various language processing tasks, including machine translation, text classification, and text generation. Meanwhile, high-quality open-source large language models like Llama, ChatGLM, and Qwen have also emerged. These models enable teams to swiftly create superior LLM applications.
However, the lack of a consistent observability experience across these frameworks complicates developers' efforts to compare and migrate between them. The challenge lies in reducing development costs while standardizing the use of OpenAI's interfaces and efficiently monitoring LLM applications' performance without increasing complexity.
GreptimeAI and BentoCloud offer practical solutions to these issues, culminating in an effective observability dashboard:
What are GreptimeDB and GreptimeAI?
GreptimeDB is an open-source time-series database focusing on efficiency, scalability, and analytical capabilities.
GreptimeAI is built on top of GreptimeDB, providing a set of observability solutions for Large Language Model (LLM) applications. It enables you to have real-time, comprehensive insights into the cost, performance, traffic, and security aspects of LLM applications, helping teams improve the reliability of LLM applications.
What are BentoML and BentoCloud?
BentoML is a unified framework designed for serving, packaging, and deploying machine learning models. It supports real-time API serving, inference optimization, batch processing, model composition, and many more for handling different AI use cases.
BentoCloud offers a serverless platform optimized for running any AI model, with autoscaling capability, security and observability.
BentoCloud provides simplified Service APIs to deploy large language models. The following is an example of a BentoML Service with OpenAI-compatible endpoints for generating responses from an LLM mistralai/Mistral-7B-Instruct-v0.2, using vLLM as the backend.
It specifies model behavior through a prompt template, sets a maximum token limit, and streams responses to ensure interactive, real-time communication.
python
import uuid
from typing import AsyncGenerator
import bentoml
from annotated_types import Ge, Le
from typing_extensions import Annotated
# Import utility for creating OpenAI-compatible endpoints. See https://github.com/bentoml/BentoVLLM.
from bentovllm_openai.utils import openai_endpoints
MAX_TOKENS = 1024
# Define a prompt tem)plate to guide the model's behavior and response style
PROMPT_TEMPLATE = """<s>[INST]
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
{user_prompt} [/INST] """
MODEL_ID = "mistralai/Mistral-7B-Instruct-v0.2"
# Decorators to mark the class as a BentoML service with OpenAI-compatible endpoints
@openai_endpoints(served_model=MODEL_ID)
@bentoml.service(
name="mistral-7b-instruct-service",
traffic={
"timeout": 300,
},
resources={
"gpu": 1,
"gpu_type": "nvidia-l4",
},
)
class VLLM:
def __init__(self) -> None:
from vllm import AsyncEngineArgs, AsyncLLMEngine
ENGINE_ARGS = AsyncEngineArgs(
model=MODEL_ID,
max_model_len=MAX_TOKENS
)
self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS)
@bentoml.api
async def generate(
self,
prompt: str = "Explain superconductors like I'm five years old",
max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS,
) -> AsyncGenerator[str, None]:
from vllm import SamplingParams
SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens)
prompt = PROMPT_TEMPLATE.format(user_prompt=prompt)
stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM)
cursor = 0
async for request_output in stream:
text = request_output.outputs[0].text
yield text[cursor:]
cursor = len(text)To understand this Service in more detail and deploy this Service to BentoCloud, see this tutorial.
Once it is up and running, you can interact with it on the BentoCloud console.
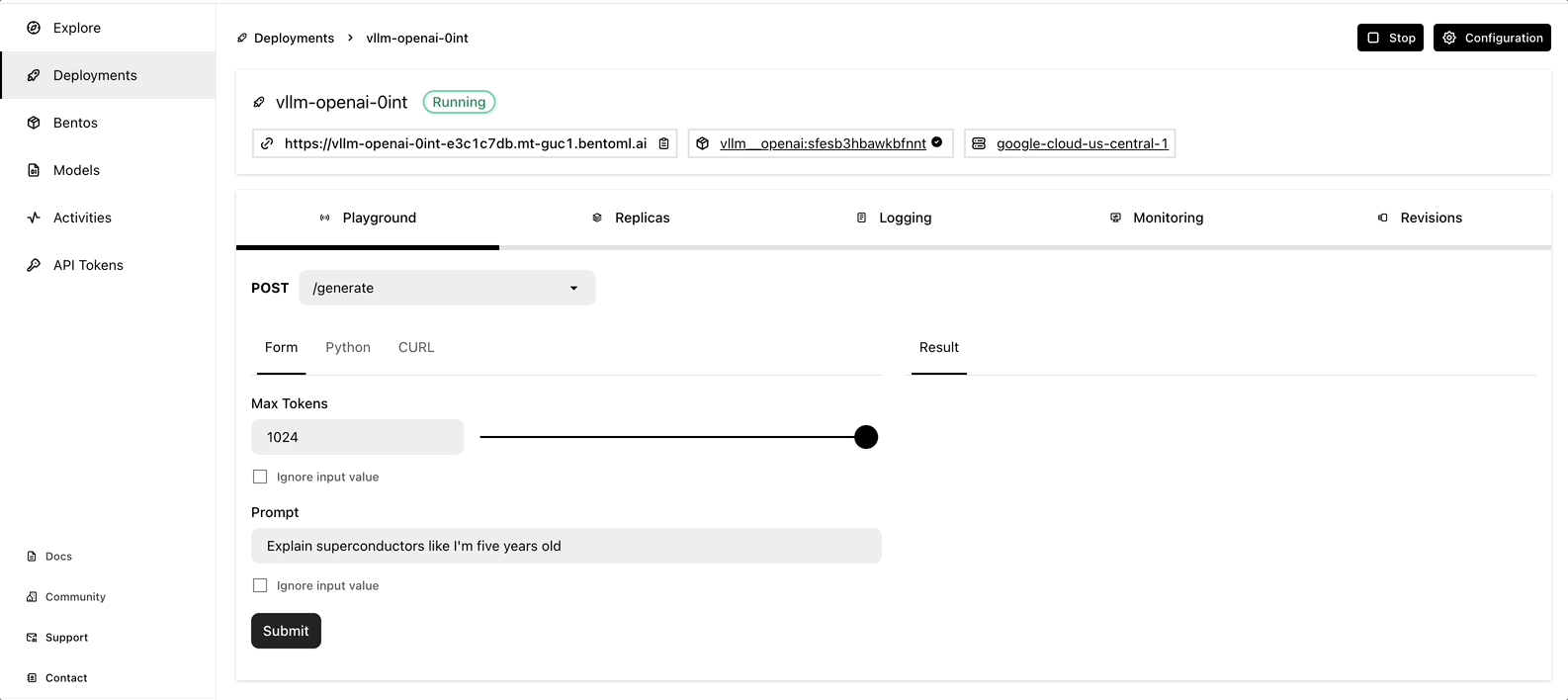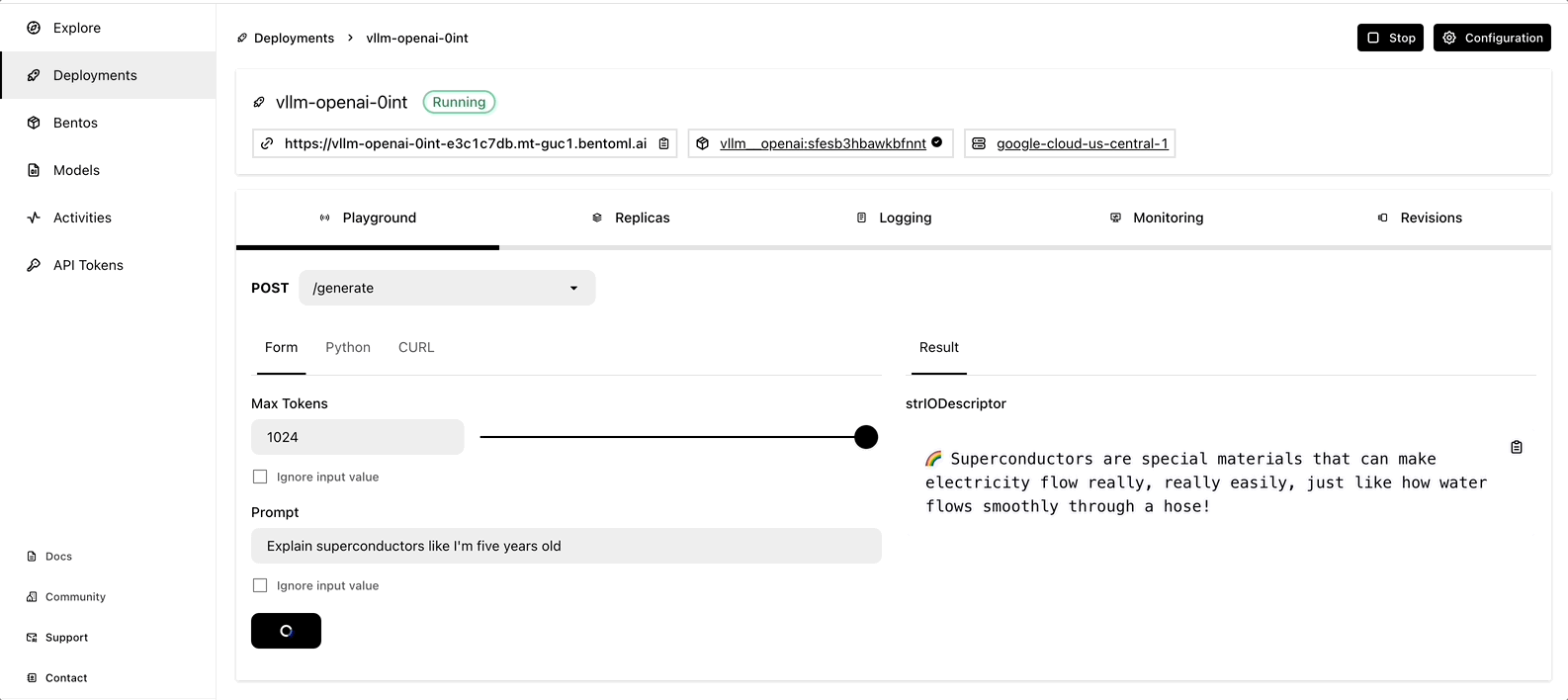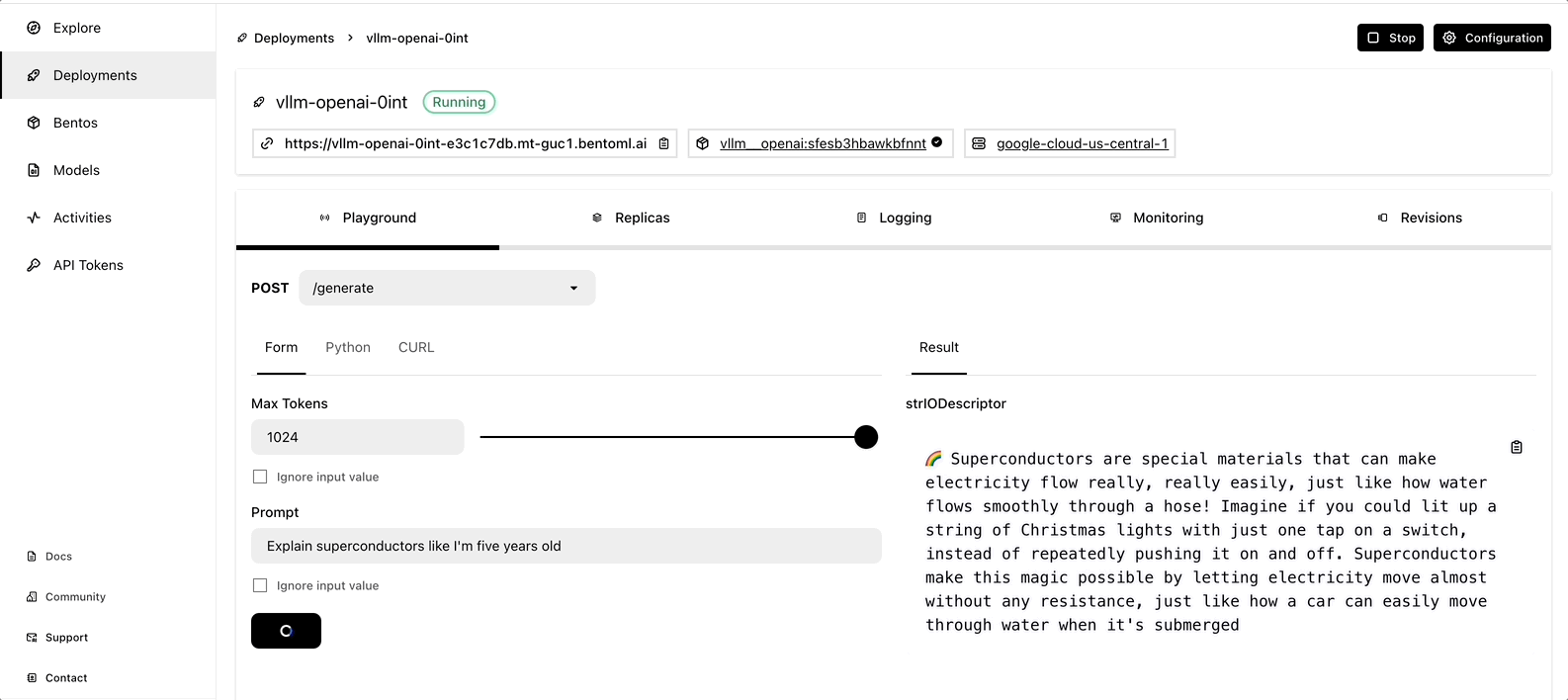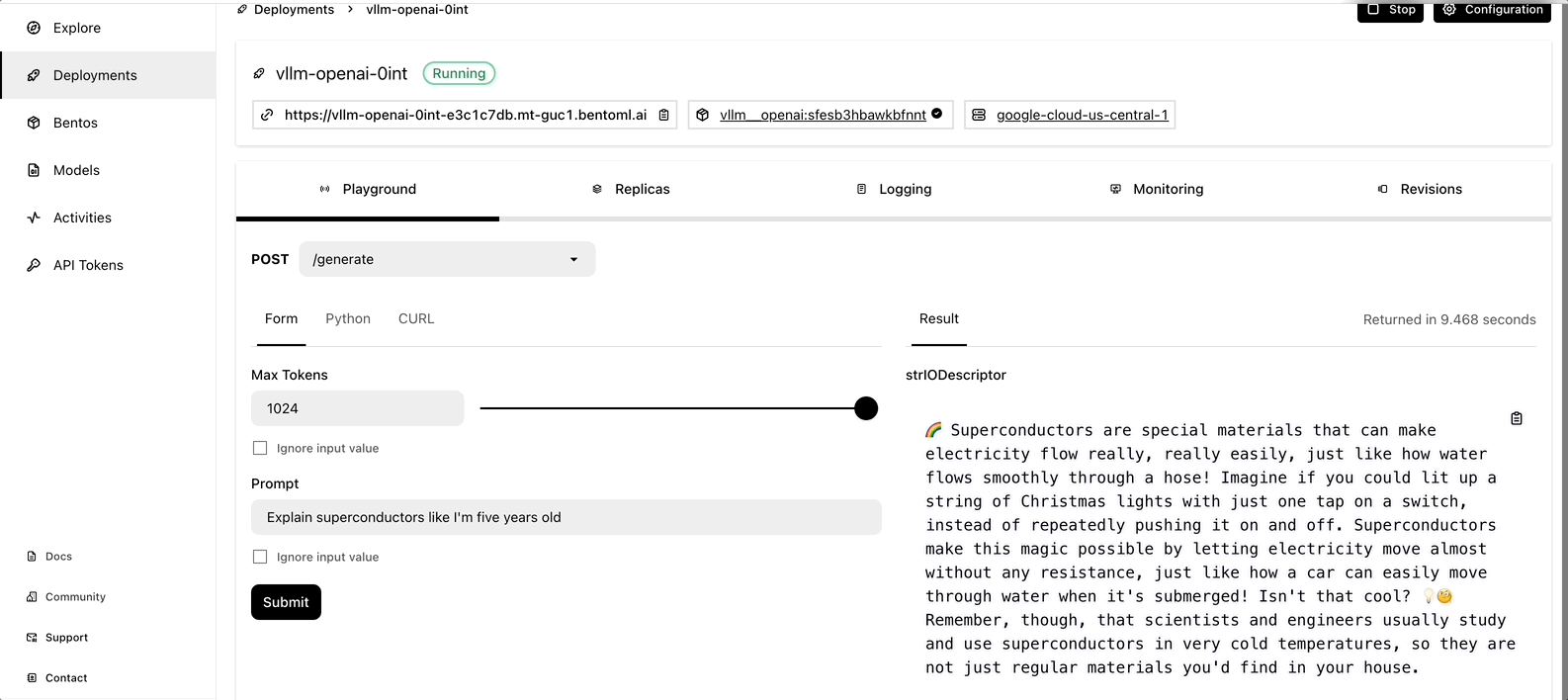
Observe LLM application via GreptimeAI
Install
bash
pip install openai greptimeaiSetup GreptimeAI credentials
Sign up GreptimeCloud for free, create a service and enter into detail. Locate the LLM Observability option under the solutions tab and toggle it to enable.
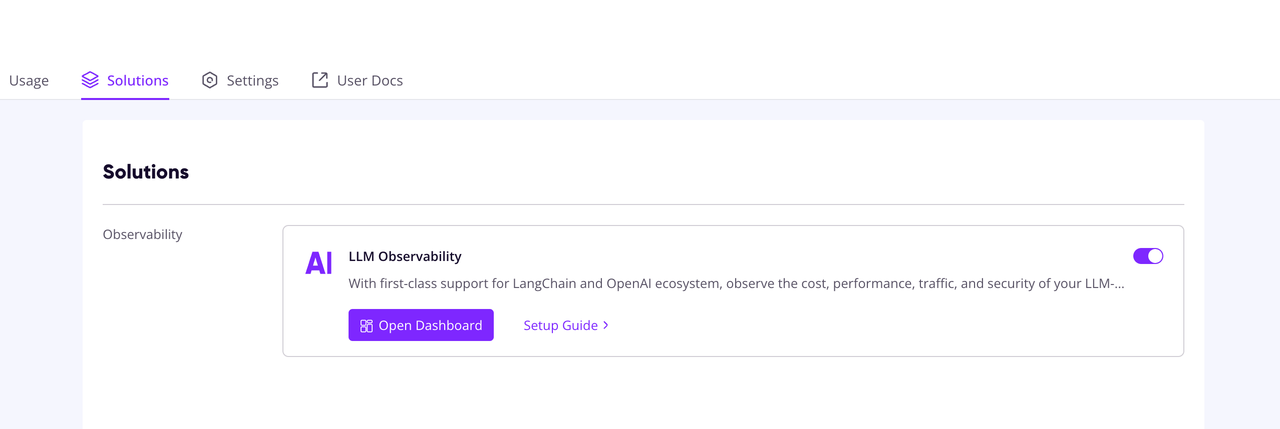
Click on the Setup Guide to view detailed guide on how to setup the credentials.
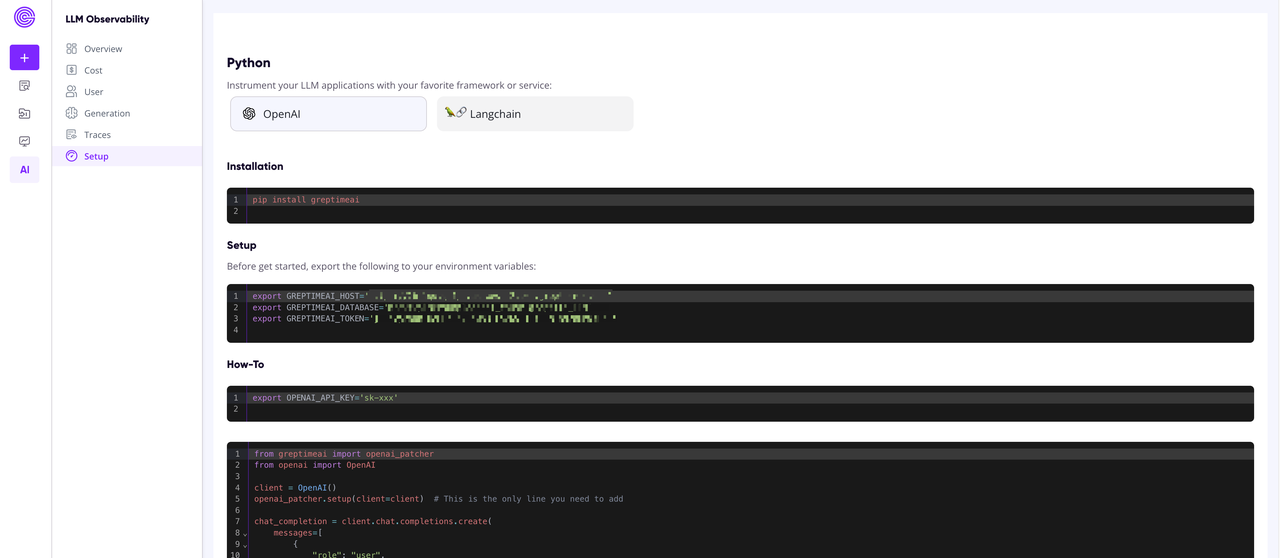
If you do not want to export these credentials as environment variables, you can directly pass the host, database and token into method openai_patcher.setup().
Patch OpenAI client
All you have to do is to patch OpenAI client as below:
python
# you can pass <host>, <database>, <token> into this setup method
# if you do not want to export the credentials as environmental variables.
openai_patcher.setup(client=client)The following is the runnable sample codes:
python
from openai import OpenAI
from greptimeai import openai_patcher
client = OpenAI(base_url='<your_bentocloud_deployment_url>/v1', api_key='na')
openai_patcher.setup(client=client)
chat_completion = client.chat.completions.create(
model="mistralai/Mistral-7B-Instruct-v0.2",
messages=[
{
"role": "user",
"content": "Explain superconductors like I'm five years old"
}
],
stream=True,
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")GreptimeAI Dashboard
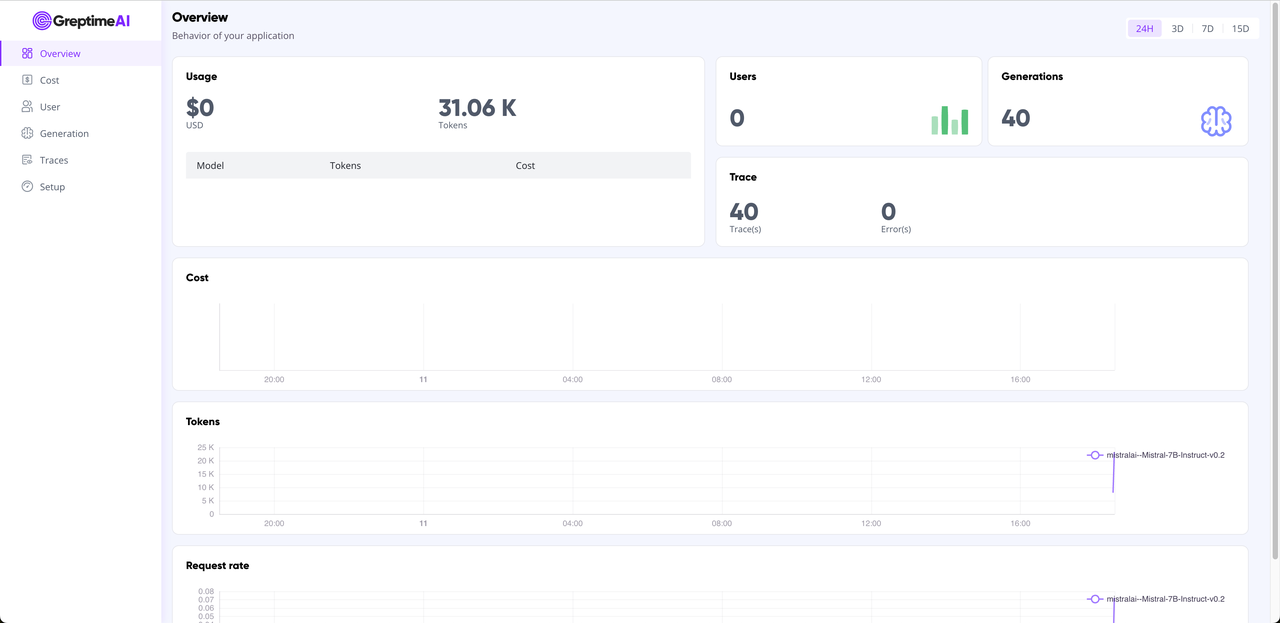
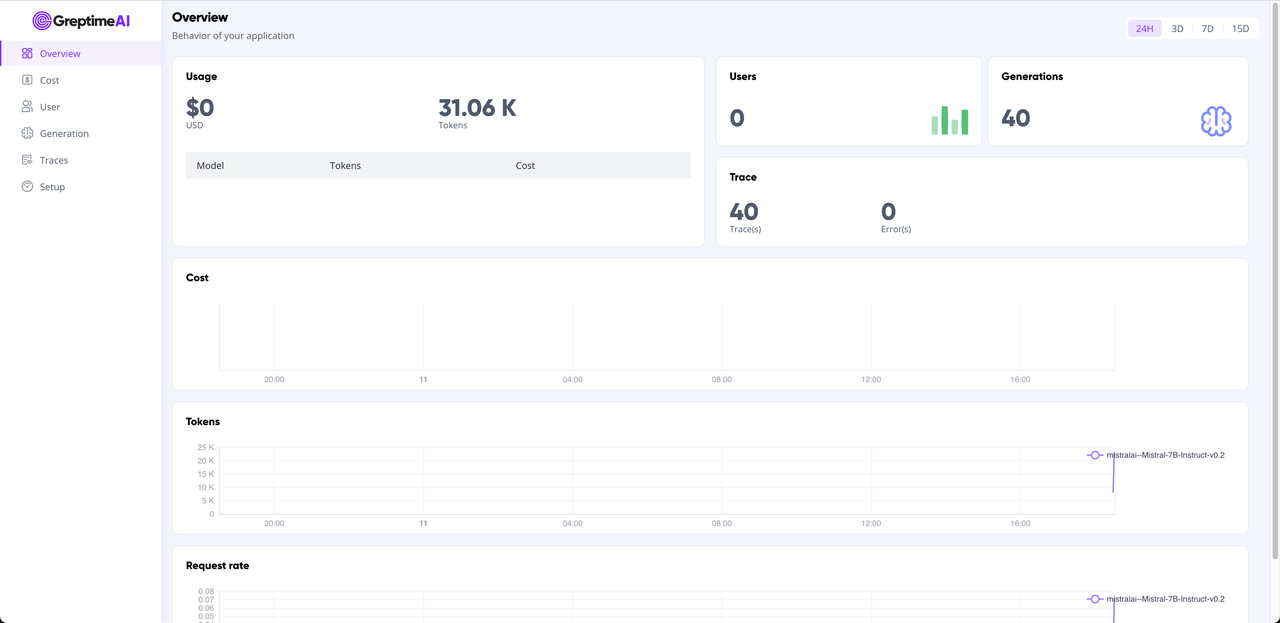
Metrics and trace data from OpenAI calls are automatically collected into the GreptimeAI service. You can view the overall usage in the GreptimeAI Overview and find valuable data you're interested in under the corresponding feature tabs.
Summary
If you're developing LLM applications with open-source large language models and aspire to utilize API calls akin to OpenAI's style, then choosing BentoCloud for managing your inference models, coupled with GreptimeAI for performance monitoring, would be a good choice. Leveraging GreptimeAI's observability features can enhance your understanding and optimization of model performance and resource utilization. GreptimeAI + BentoCloud is designed to support the development of production-grade LLM applications.
We encourage you to explore the GreptimeAI + BentoCloud Cloud solution and share your experience and insights with the community.




