
On this page
Everything is connected. New applications are almost on the cloud. DevOps needs to observe them. These trends lead to the need for increasingly large amounts of time series data to be stored efficiently and analyzed flexibly.
So, how can an enterprise leverage robust time-series data analyzing capabilities while keeping the Total Cost of Ownership (TCO) within manageable bounds?
Traditional technologies like InfluxDB and Prometheus are facing significant challenges and expenses due to their limitations in scaling beyond a single machine. Even though some vendors offer cluster solutions, these often suffer from inefficient resource utilization due to their lack of elasticity.
We introduce GreptimeDB which benefits users with elasticity and commodity storage on the cloud, offering a fast and cost-effective solution to store and analyze your time series data at any scale.
The Cost Impact of Traditional Time Series Data Stack
Time series data is generated every second with sensors reporting metrics and applications logging continuously. The observability of systems relies on analyzing these kinds of time series data in real-time.
In a perfect world, you would query the data as if they were ready to use efficiently, without considering cost, time investment, or impact on the business. In reality, budgets and time are finite, and the cost is a major constraint for building a time series data stack.
The cost to implement such data stacks includes not only the "Day 1" capital expenses tied to setting up the system, but also the significant "Day 2" operational expenses required to maintain the system.
Capital Expenses
Capital expenses require an up-front investment. Traditional technologies would typically require enterprises to purchase hardware dedicated for the deployment, which is large acquisition contracts.
To ensure service's availability, the provisions are often calculated based on the maximum load and storage estimates, which introduces an significant extra buffer beforehand.
Moreover, time series data stacks built upon traditional technologies would deploy heterogeneous systems, each with its dedicated resources, resulting in a heavy combination of message queues, online time series libraries, offline data warehouse, and data replication and transformation intra- or inter-systems: You have to pay for all of them!
Operational Expenses
Operational expenses are gradual and spread out over time. They include, but are not limited to, manpower, time, and financial resources devoted to tasks like debugging, troubleshooting performance issues, system upgrades, adjusting configurations for optimal data flow, and managing security advisory.
Similarly, managing heterogeneous systems requires separate operational efforts with different skills. Enterprises have to build a huge operating team to cover all these aspects.
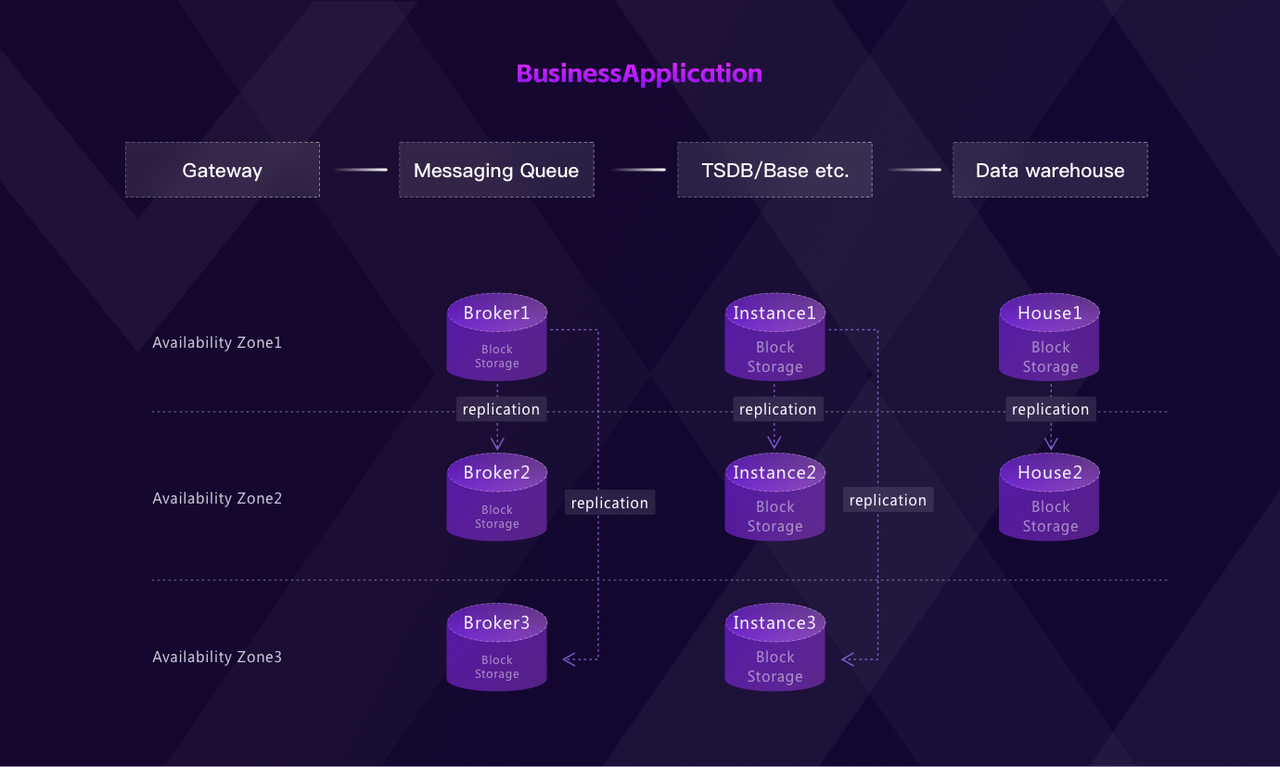
Employing cloud-native infrastructure can essentially reduce the operational costs of manual data replication. A solution that provides a centralized console can significantly reduce maintenance overhead.
Opportunity Cost
Enterprises managing their own time series data stacks, especially with heterogeneous systems, face significant opportunity costs. They divert valuable resources from core business operations and strategic initiatives by allocating highly skilled employees to these tasks.
Why You Need GreptimeDB Today
While traditional time series data stacks play a crucial role in businesses, there is a large demand for alternatives.
Here comes GreptimeDB, an open-source time-series database focusing on efficiency, scalability, and analytical capabilities.
Over the past few years, the creators have built an ultra-large-scale data processing system specifically for time series in a world-class fintech company. They have managed to write hundreds of millions of data points per second uninterruptedly, analyze millions of indicators in multidimensional and real-time (for alerts, root cause analysis, etc.), and store tens of millions of legacy metrics at very low cost.
Based on these best practices, GreptimeDB provides an alternative to your time series data stack with a smooth upgrade path.
- Performance. GreptimeDB implements flexible indexing capabilities and a distributed, parallel-processing query engine, tackling high cardinality issues down.
- Analyzing all types of time-series data. GreptimeDB embraces the broad analytics ecosystem and easily queries metrics, logs, events, and traces with standard SQL and PromQL.
- Drop-in replacement. GreptimeDB widely supports data protocols, including SQL, InfluxDB, OpenTelemetry, Prometheus Remote Storage, and more.
You can read the TSBS benchmarks for GreptimeDB v0.8 and the protocols that GreptimeDB supports for read and write.
How GreptimeDB can improve cost-efficiency
GreptimeDB offers several key cost-saving advantages:
- Adaptive data compression. Optimized columnar layout for handling time-series data; compacted, compressed data lossless over 30x cost efficiency.
- Elasticity and commodity storage. Data is primarily stored on various storage backends, particularly cloud object storage, with 50x cost efficiency (compression counted).
- Reduced downtime. Datanodes are stateless. A new datanode can take over a lost one promptly. This minimizes system outages. Storage reliability is tied to cloud object storage (99.999999999% durability and 99.99% availability for S3).
- Elimination of heterogeneous systems. GreptimeDB is built with powerful analytics supports. It provides SDKs for multiple languages as well as supports a wide range of ingestion protocols. You can use GreptimeDB solutions as a one-stop time series data stack.
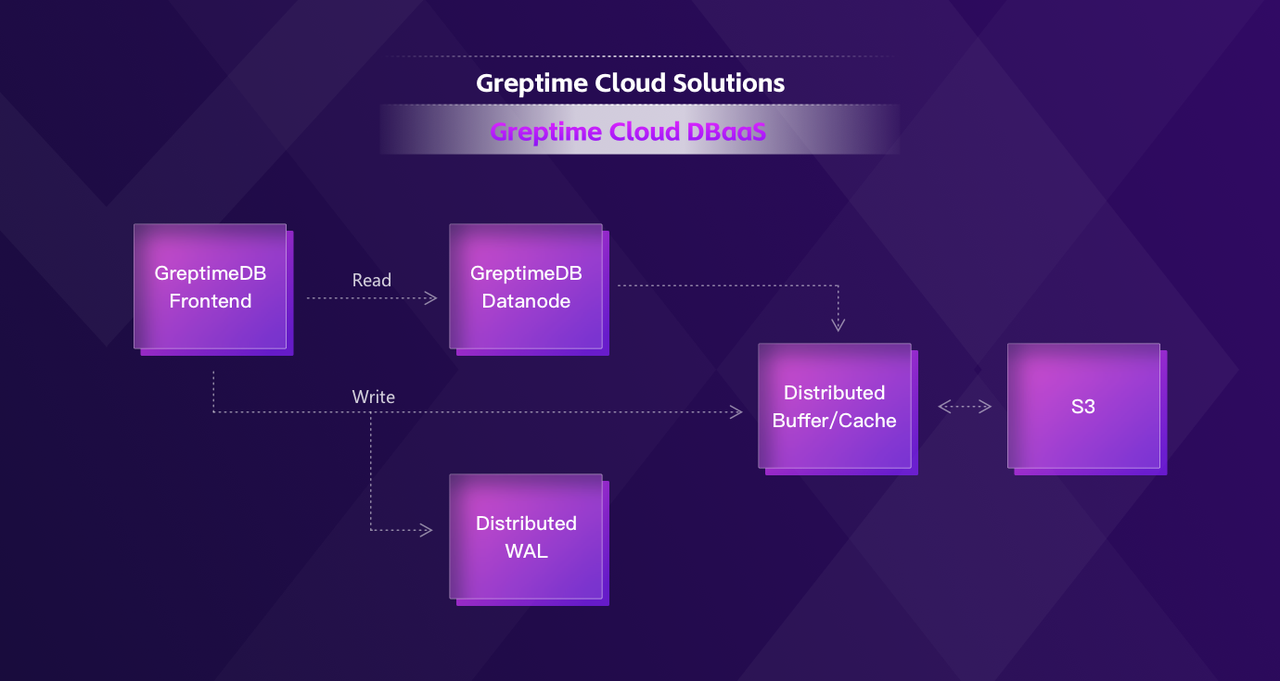
GreptimeDB presents a highly compelling option for enterprises seeking to enhance the efficiency and cost-effectiveness of their time series data stack.
Case Study: Edge-Cloud Integrated Solution
A leading international electric car manufacturer has integrated GreptimeDB's Edge-Cloud Integrated TSDB solution, a time-series database solution deeply embedded in real-world business scenarios of automobile companies.
Prior to adopting GreptimeDB, they developed an in-house data stack with multiple technologies, which encountered the following challenges:
- High data-related costs. Each car costs hundreds of dollars annually.
- Weak write, query and analysis capabilities at the edge. Only the cloud database can do analysis, resuluting in a complex tech combination to coordinate edge (vehicle) and cloud.
- Difficult to obtain valuable insights due to data inaccuracy. Data can only be obtained at minute or second frequency because of performance and cost concerns.
GreptimeDB solution provides a one-stop time series data stack to resolve all challenges above:
- Vehicle-side traffic costs cut to 1/10; storage and compute costs on cloud cuts to 1/30 with data lossless compression.
- Written in Rust, GreptimeDB can be deployed on the vehicles. The embedded database drastically reduces the development workload required to improve data quality.
- Millisecond-level precision achieved for processing and usage of time series data for all vehicles with controlled costs.
Overall, it saves more than one hundred dollars for each car annually. Read the blog for an explained analysis.
Conclusion
In summary, time series data stacks are essential, but the traditional solutions come with significant costs and operational burdens. GreptimeDB offers a cost-effective, scalable, and efficient alternative, designed to meet modern enterprise needs.
By leveraging GreptimeDB, organizations can significantly reduce their total cost of ownership, improve performance, and streamline their time series data stack, freeing up resources for core business operations and strategic initiatives. GreptimeDB's innovative approach to time series data management makes it valuable to any data-driven enterprise.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




