On this page
In GreptimeDB v0.9, we added support for Logs: Pipeline engine and full-text indexing. GreptimeDB aims to be the unified time-series database for Metrics, Logs, Events, and Traces. Before v0.9, users could write text (string) data but couldn't perform customized parsing and querying. With the Pipeline engine and full-text indexing, users can process log data directly using GreptimeDB, significantly improving the data compression ratio and supporting quick retrieval of target log data through fuzzy query.
This article will briefly introduce the design principles and implementation steps of the Pipeline engine in GreptimeDB.
Design Goals and Advantages
When we think of logs, the first thing that comes to mind is often a long string. Here’s an example of a classic nginx access log entry:
192.168.97.8 - - [15/Oct/2024:08:41:09 +0000] "GET /query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38 HTTP/1.1" 200 664 "https://www.github.com" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0"Although this log entry is a long string, it contains structured information such as IP (192.168.97.8), timestamp ([15/Oct/2024:08:41:09 +0000]), request method, request path, HTTP protocol version, HTTP status code, etc. Despite strings being unstructured data, most logs we encounter are printed by log middleware, which usually includes specific information at the beginning of the log, such as timestamps, log levels, and some kind of tags (e.g., application name or method name).
If we treat this string as a whole and store it in a column, queries for information within the log body can only be performed using the like syntax in SQL. This makes queries cumbersome and inefficient, for example, finding request paths with HTTP status code 200.
If we can parse the log string into different columns upon receiving the log, the efficiency of ingestion and querying will be greatly improved. Some readers might have recognized this as the ETL process. For now, products out there supporting parsing input text often require an independent deployment, adding resource overhead and operational complexity.
Now the design goal is clear. We want to add a simple processing workflow when GreptimeDB receives log data, allowing fields within the string to be extracted and transformed into different data types and field values, and storing these values in columns in the same table. Furthermore, the conversion rules should be described using configuration files, allowing different logs to be processed with different processing rules.
Compared to storing string text directly, parsing and storing structured data brings two significant benefits:
- Extracting and storing semantic data improves query efficiency
For example, we can store the HTTP status code as a separate column, making it easy to query all log strings with status code 200.
- Improving data compression ratio
For text compression, tools like gzip can achieve a near-optimal compression ratio; database compression and storage for pure text are unlikely to be better. By parsing log strings and transforming them into different data types accordingly (e.g., converting HTTP status code to int), the database can use techniques like Run-Length Encoding and columnar compression to further improve compression ratio. Our tests show that the storage size can be reduced by at least 50% compared to general text compression.
Design Decisions
We use the previous log as an example to demonstrate the process.
192.168.97.8 - - [15/Oct/2024:08:41:09 +0000] "GET /query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38 HTTP/1.1" 200 664 "https://www.github.com" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0"For the configuration format, we refer to Elasticsearch's Ingest processor. Each processor operates independently, while processors can be added or expanded easily. Also, processors can be combined to handle more complex scenarios.
Processor is used to perform extracting and processing on fields, such as splitting the string into substrings to obtain fields like HTTP status code "200". We also want to transform the string into more efficient types, such as numeric types. Therefore, we need a way to transform parsed substring fields into data types supported by the database. Here, we introduce a simple built-in type conversion system Transform to handle this situation.
Based on the observed log string pattern, we can write the following configuration.
yaml
processors:
- dissect:
fields:
- line
patterns:
- '%{ip} %{?ignored} %{?ignored} [%{ts}] "%{method} %{path} %{protocol}" %{status} %{size} "%{referer}" "%{ua}"'
- date:
fields:
- ts
formats:
- "%d/%b/%Y:%H:%M:%S %Z"
transform:
- fields:
- status
- size
type: int32
- fields:
- ip
- method
- path
- protocol
- referer
- ua
type: string
- field: ts
type: time
index: timeFirst, we use Processor to process the data. Using Dissect Processor, we extract different fields from a log string and use Date Processor to parse the date string into a timestamp. Then, we use Transform to transform the extracted fields into database-supported data types, such as int32.
Note that the field names set in Transform will also be used as column names. Finally, we can specify whether the field needs to be indexed in the database, i.e., setting the ts field as the time index in GreptimeDB.
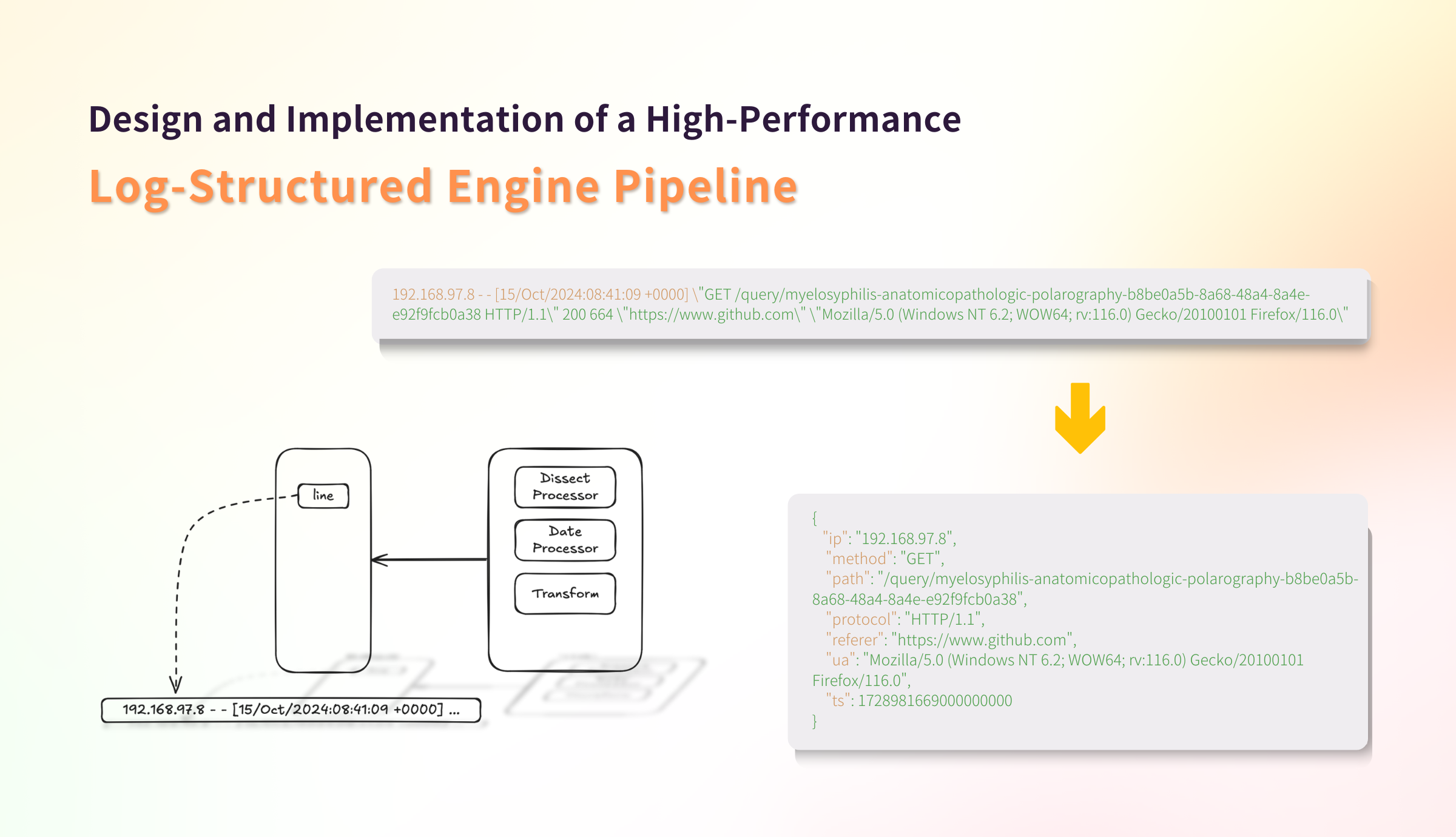
The data processing flow is straightforward, as shown in the figure below.

Implementation Details
Our interface supports receiving multiple log strings simultaneously as an array. To process the array, we simply iterate through each line. In the following example, we'll illustrate the data processing flow using the log string above.
For processing, we divide the overall logic into two parts in terms of space: data context and 'code'.
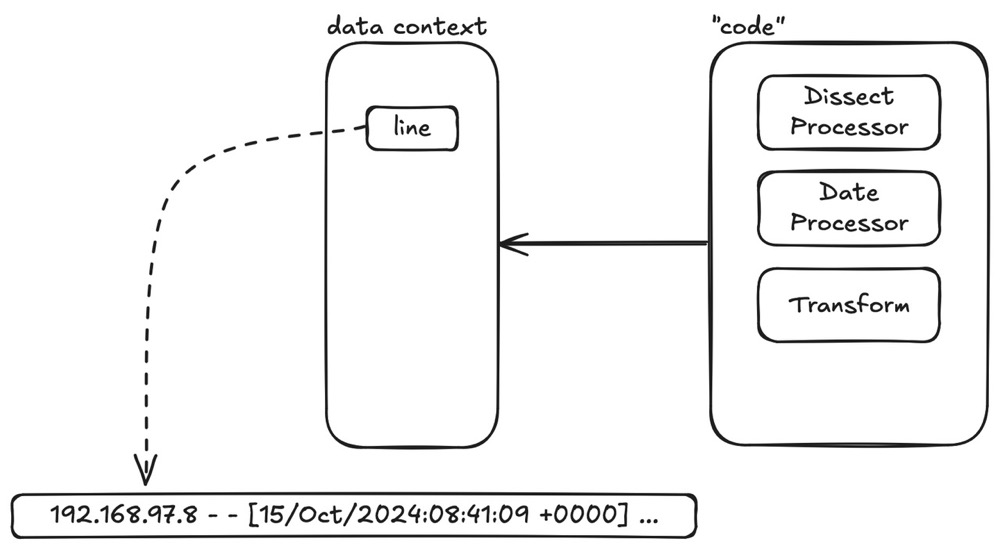
The data context is a logical space where data is stored in a key-value manner: each data has its name (key) and value (value). The initial state of the context contains the original log input line, as shown below (represented in JSON format for convenience):
json
{
"line": "192.168.97.8 - - [15/Oct/2024:08:41:09 +0000] \"GET /query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38 HTTP/1.1\" 200 664 \"https://www.github.com\" \"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0\""
}The code is the Processor and Transform defined by configuration files. First, we need to load and parse the configuration file into the program. This part of the logic mainly involves defining and loading the configuration file, not log processing, so it is not covered in this article.
Let's use the Date Processor as an example. The code structure for Processor is approximately as follows:
rust
pub struct DateProcessor {
// input fields
fields: Fields,
// the format for parsing date string
formats: Formats,
// optional timezone param for parsing
timezone: Option<String>,
}The key method of Processor is as follows:
rust
pub trait Processor {
// execute processor
fn exec_field(&self, val: &Value) -> Result<Map, String>;
}For each Processor, we invoke the exec_field method to process the data in the data context. The Processor uses the field name specified in the configuration file (essentially the key in the data context) to retrieve the corresponding value. After processing the value through the Processor's logic, we put the output back into the data context. This is the processing flow of a Processor.
We take the first Dissect Processor as an example to demonstrate the processing flow. In the initial state, the data context only contains the original input, as shown below:
json
{
"line": "192.168.97.8 - - [15/Oct/2024:08:41:09 +0000] \"GET /query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38 HTTP/1.1\" 200 664 \"https://www.github.com\" \"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0\""
}Here is the definition of the Dissect Processor in configuration:
yaml
processors:
- dissect:
fields:
- line
patterns:
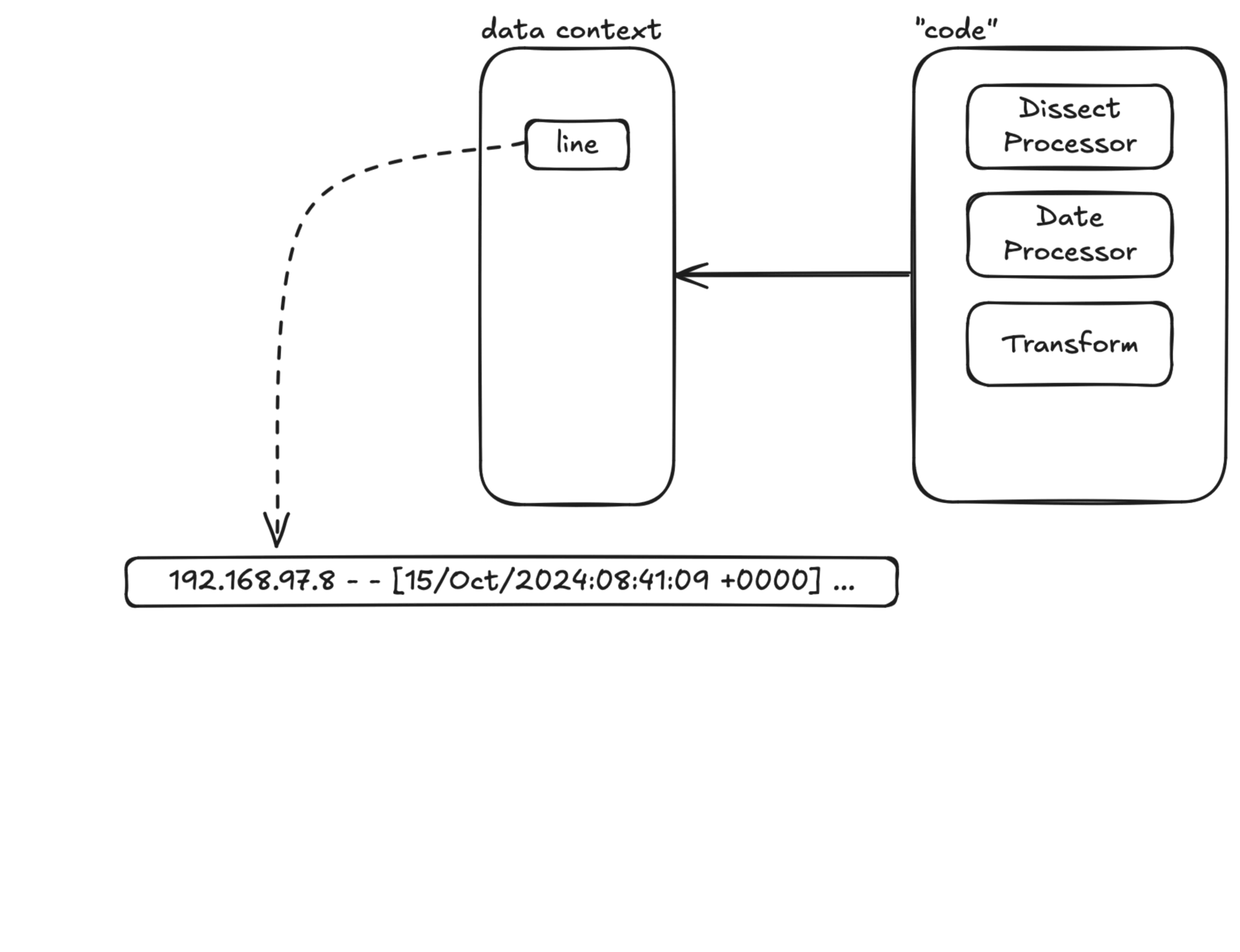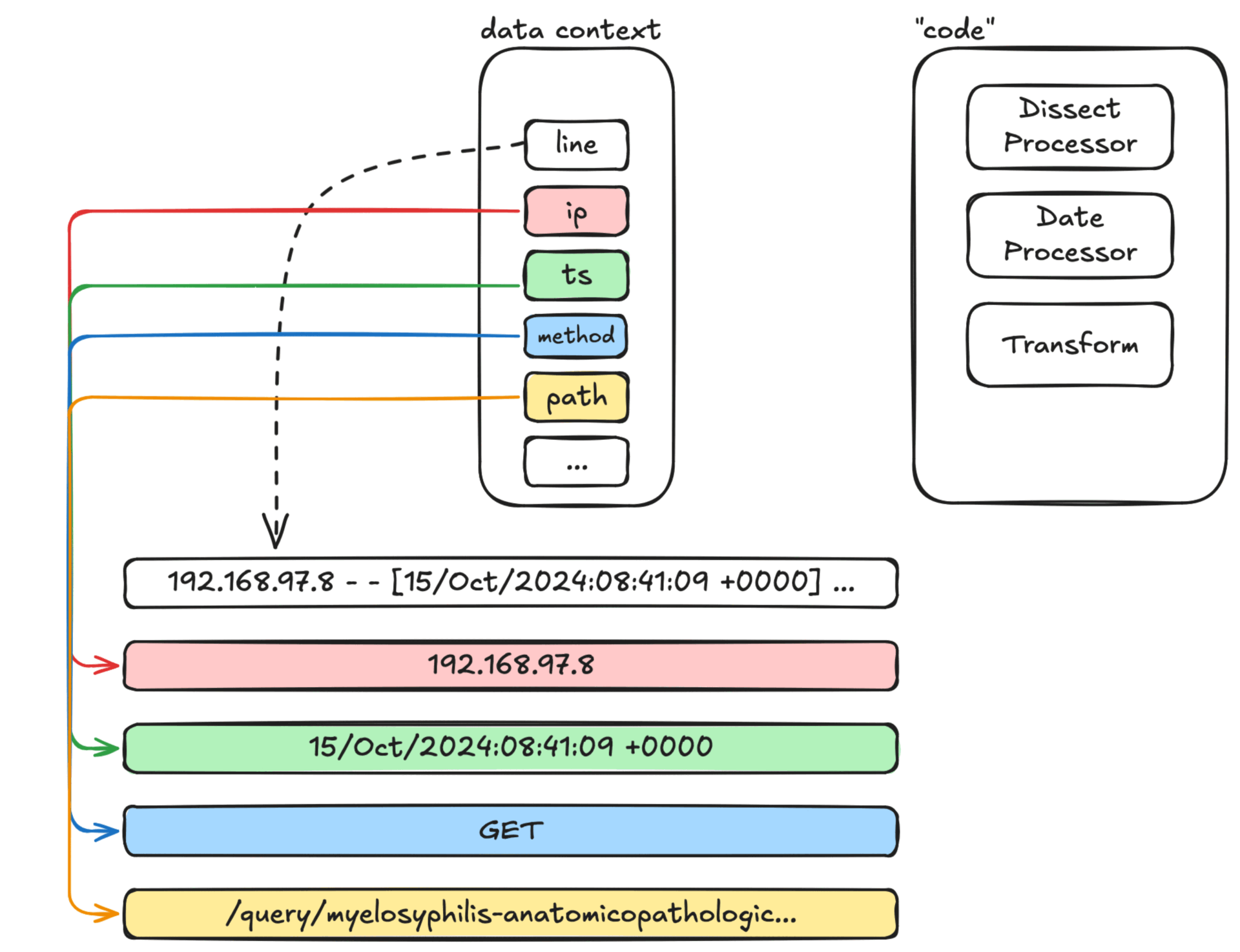
- '%{ip} %{?ignored} %{?ignored} [%{ts}] "%{method} %{path} %{protocol}" %{status} %{size} "%{referer}" "%{ua}"'The Dissect Processor splits the text based on spaces or simple punctuation marks and associates substrings with the key names specified in the pattern, storing them back in the data context. In this example, we first get the value corresponding to the key line from the data context, then split the text, assign the split results to names like ip and ts correspondingly, and finally store these fields back into the data context.
The state of the data context after the process is shown below:
json
{
"line": "192.168.97.8 - - [15/Oct/2024:08:41:09 +0000] \"GET /query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38 HTTP/1.1\" 200 664 \"https://www.github.com\" \"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0\"",
"ip": "192.168.97.8",
"ts": "15/Oct/2024:08:41:09 +0000",
"method": "GET",
"path": "/query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38",
"protocol": "HTTP/1.1",
"status": "200",
"size": "664",
"referer": "https://www.github.com",
"ua": "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0"
}
By executing the Processors defined in the rule configuration in sequence, the data processing is done.
After processing, the data may still not be in the final desired format. For example, in the previous case, we extracted the status field, but it remains a string. Transforming this string to a numeric format can improve both storage efficiency and query performance. This additional layer of processing is defined as Transform.
The structure of a Transform is generally as follows:
rust
pub struct Transforms {
transforms: Vec<Transform>,
}
pub struct Transform {
// input fields
pub fields: Fields,
// target datatype for database
pub type_: Value,
// database index hint
pub index: Option<Index>,
}It is very straightforward. For each Transform, we get the value from the data context through fields, transform it into the data type specified by type_, and then store it back into the data context.
At this point, we have completed the parsing process of the original unstructured log string, donating relatively structured fields (columns) and corresponding values. The result is as follows:
json
{
"line": "192.168.97.8 - - [15/Oct/2024:08:41:09 +0000] \"GET /query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38 HTTP/1.1\" 200 664 \"https://www.github.com\" \"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0\"",
"status": 200,
"size": 664,
"ip": "192.168.97.8",
"method": "GET",
"path": "/query/myelosyphilis-anatomicopathologic-polarography-b8be0a5b-8a68-48a4-8a4e-e92f9fcb0a38",
"protocol": "HTTP/1.1",
"referer": "https://www.github.com",
"ua": "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:116.0) Gecko/20100101 Firefox/116.0",
"ts": 1728981669000000000
}So far, we have completed the extraction and processing of the data. The remaining part is to convert this data into an insert request and ingest it into the database. Interested readers can check the code of this version here to find out the detailed code execution process of the original Pipeline engine.
Conclusion
This article introduces the design principles and implementation of the Pipeline engine in GreptimeDB v0.9.0. Readers will see that the entire process is a straightforward interpreter-like implementation. For further insights, refer to the tutorial here. In practice, we've optimized and refactored pipeline execution several times, resulting in a version that's substantially evolved from the original. Stay tuned for upcoming articles exploring these improvements.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




