On this page

From version 0.9 to 0.10, the Greptime team achieved remarkable progress: we merged 422 commits, modifying 1,120 files. These updates included 142 feature enhancements, 103 bug fixes, 39 code refactorings, and extensive testing efforts. During this time, 8 individual contributors from the community made 48 valuable contributions.
A heartfelt thanks to the team and all contributors for their dedication! We warmly invite more tech enthusiasts to join us on this journey.
Log Enhancements
Loki Remote Write
- GreptimeDB now supports the Loki Remote Write protocol. Log data in Loki format can be ingested using the
loki.writecomponent of Grafana Alloy or Grafana Agent.
- GreptimeDB now supports the Loki Remote Write protocol. Log data in Loki format can be ingested using the
Pipeline Engine Optimization
In v0.10, we have significantly improved the performance of the Pipeline Engine. Even under relatively complex configurations, its processing speed has increased by more than 70% compared to version 0.9.
Introduced a JSON Path Processor, enabling data extraction using JSON Path.
Vector Plugin Support
- Added a
greptime_logssink, allowing support for a wide range of ingestion protocols via Vector.
- Added a
OTeL Log Support
With our support for JSON data types, GreptimeDB now enables Logs ingestion via OTLP. Additionally, we’ve restructured the storage schema for Traces. With this update, GreptimeDB fully supports OTLP ingestion for Metrics, Traces, and Logs, making it a true unified database for all observability data types.
For more information and user guide, please refer to the documentation here.
Flexible Indexing
In previous versions, inverted index was always bound to the declaration of the PRIMARY KEY. By default, all PRIMARY KEY columns automatically had inverted indexes created for them. This default behavior was generally reasonable for most scenarios, as inverted indexes on all primary keys boost query performance and serve as a key performance guarantee in typical use cases.
However, as GreptimeDB's use cases continue to grow, certain user requirements have surfaced that the default behavior cannot fully accommodate:
- Deemphasizing Certain Primary Key Columns
- In some cases, users declare a column as a primary key only to ensure deduplication, without needing to accelerate queries. For example, in the Prometheus Remote Write protocol, tags are mapped to primary keys in GreptimeDB, but not all tag columns require faster query performance.
- Creating Inverted Indexes on Non-Primary Key Columns
- In log scenarios, certain fields may not align with the semantics of tags but still benefit from accelerated queries through inverted indexing.
With the latest version, inverted index is no longer forcibly tied to PRIMARY KEY columns. You can now create inverted indexes on any column as needed. This flexibility provides significant advantages in cost and efficiency while also alleviating high cardinality issues to some extent.
JSON Data Type
GreptimeDB now enables users to store and query JSON-formatted data. This highly flexible type can accommodate both structured and unstructured data, making it ideal for scenarios such as logging, analytics, and semi-structured data storage.
How to Use the JSON Data Type in GreptimeDB
- Define a JSON Column
Use the following syntax in SQL to define a table with a JSON column:
sql
CREATE TABLE <table_name> (
...
<json_col> JSON
);- Insert JSON Data
JSON data in GreptimeDB is written as strings. Example of inserting JSON data using SQL:
sql
INSERT INTO <table> (<json_col>) VALUES
('{"key1": "value1", "key2": 10}'),
('{"name": "GreptimeDB", "open_source": true}'),
...- JSON Functions
GreptimeDB provides a variety of JSON functions (e.g., json_get_<type>, json_is_<type>, json_path_exists) for manipulating JSON data. Refer to the documentation for a full list of JSON functions.
Example query:
sql
SELECT <json_function>(<json_col>, <args>) FROM <table>;Enhanced ALTER Function
- Added support for modifying the data TTL(Time To Live) for both databases and Tables.
sql
ALTER TABLE my_table SET 'ttl'='1d';
ALTER DATABASE my_db SET 'ttl'='360d';
ALTER TABLE my_table UNSET 'ttl';
ALTER DATABASE my_db UNSET 'ttl';- Allow modification to some parameters of compaction, such as:
sql
# The time window parameter of TWCS compaction strategy.
ALTER TABLE monitor SET 'compaction.twcs.time_window'='2h';
# The maximum allowed output file size of TWCS compaction strategy.
ALTER TABLE monitor SET 'compaction.twcs.max_output_file_size'='500MB';
# The maximum allowed number of files in the inactive windows of TWCS compaction strategy
ALTER TABLE monitor SET 'compaction.twcs.max_inactive_window_files'='2';
# The maximum allowed number of files in the active window of TWCS compaction strategy
ALTER TABLE monitor SET 'compaction.twcs.max_active_window_files'='2';
# The maximum allowed sorted runs in the inactive windows of TWCS compaction strategy
ALTER TABLE monitor SET 'compaction.twcs.max_inactive_window_runs'='6';
# The maximum allowed sorted runs in the active window of TWCS compaction strategy
ALTER TABLE monitor SET 'compaction.twcs.max_active_window_runs'='6';- Supports enabling and disabling full-text indexing for columns
sql
# Enable Full-Text Index
ALTER TABLE monitor MODIFY COLUMN load_15 SET FULLTEXT WITH (analyzer = 'Chinese', case_sensitive = 'false');
# Disable Full-Text Index
ALTER TABLE monitor MODIFY COLUMN load_15 UNSET FULLTEXT;Query Performance Improvements
Optimized scan logic when no time range is specified. For users storing long-range data, this optimization avoids loading all metadata from object storage during queries.
Enhanced performance for certain key time-series query scenarios. For example, querying the latest N rows by timestamp (
ORDER BY timestamp DESC LIMIT N) can achieve nearly a 10x performance boost.
Other Updates
Geospatial Types Added geospatial functions for trajectories and geocoding, with support for Geohash, H3, and S2 indexes. Refer to the official documentation for details here.
Introduced vector data types. In edge scenarios such as IoT-enabled vehicle systems, GreptimeDB leverages its efficient and lightweight architecture to run seamlessly on edge devices.It enables high-performance storage and computation of vector data, providing robust support for real-time perception, intelligent decision-making, and low-latency responses in various edge systems.
This drives the deep integration of AI technologies into edge computing areas like intelligent driving.
- Flow Stream Processing
Performance Optimization: Significantly improved performance, reducing CPU overhead for streaming
COUNT(*)Flow tasks to 1% of the original.Improved Usability: Added support for
CREATE OR REPLACE FLOW.
Upgrade Instructions
Overview of Configuration File Changes
This upgrade introduces the following adjustments to the Datanode configuration file:
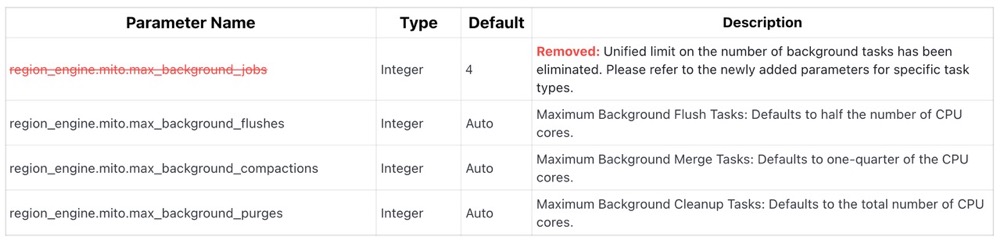
Upgrade from v0.9 to v0.10
- Check the Configuration File
- Remove the
region_engine.mito.max_background_jobsparameter:
This parameter has been removed in the new version. It was previously used to limit the total number of background tasks, but has now been replaced with more specific task type limits (e.g., Flush, Compaction, Cleanup tasks).
If this parameter is present in the configuration file, delete it and adjust the values based on the new parameters.
- New Parameter Adjustments
- Adjust the following parameters to replace the old functionality:
Use
region_engine.mito.max_background_flushesto set the maximum number of background flush tasks (default: 1/2 of the CPU cores).Use
region_engine.mito.max_background_compactionsto set the maximum number of background compaction tasks (default: 1/4 of the CPU cores).Use
region_engine.mito.max_background_purgesto set the maximum number of background purge tasks (default: the number of CPU cores).
- Based on the value of
max_background_jobsin the previous configuration, redistribute the values of the new parameters to meet performance requirements.
Upgrade from earlier versions to v0.10
Upgrading from earlier versions to v0.10 requires downtime, and it is recommended to use the official upgrade tool, with the following upgrade process:
Create a new v0.10 cluster.
Stop traffic to the old cluster (disable writes).
Export table schemas and data using the GreptimeDB CLI upgrade tool.
Import data into the new cluster using the same tool.
Redirect traffic to the new cluster.
For detailed upgrade guides, please refer to our documentation here.
Future Outlook
GreptimeDB aims to evolve into a generalized time-series database integrating metrics and logs. In the next release, we will continue refining the Log Engine to enhance log query performance and user experience. Planned improvements include:
Expanding the functionality of GreptimeDB's log query DSL.
Implementing partial compatibility with Elasticsearch/Loki APIs.
These enhancements will provide users with more efficient and flexible log query capabilities. Stay tuned and feedback welcomed!
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.