On this page
Introduction
GreptimeDB is an open-source, cloud-native observability database built for metrics, logs, and traces. It delivers real-time insights at any scale, from edge to cloud. To support diverse ingestion needs, the GreptimeDB Rust client offers two different modes:
- Low-latency Write API: Ideal for real-time or interactive workloads.
- High-throughput Bulk Stream Insert API: Designed for batch processing and data ingestion pipelines.
This guide walks through the high-throughput Bulk Stream Insert API—covering its internal design, usage patterns, optimization knobs, and real-world benchmarks.
Write Modes Overview
Low-latency Write API
Best for: Real-time applications, IoT sensors, interactive systems
Characteristics:
- Latency: Sub-millisecond
- Throughput: 1K–10K rows/sec
- Memory: Low under moderate load; may accumulate under high concurrency
- Networking: Request-response model
Example Code
rust
use greptimedb_ingester::api::v1::*;
use greptimedb_ingester::client::Client;
use greptimedb_ingester::helpers::schema::*;
use greptimedb_ingester::helpers::values::*;
use greptimedb_ingester::{database::Database, Result, ColumnDataType};
#[tokio::main]
async fn main() -> Result<()> {
// Connected to GreptimeDB
let client = Client::with_urls(["localhost:4001"]);
let database = Database::new_with_dbname("public", client);
// Definited sensor's data schema
let sensor_schema = vec![
tag("device_id", ColumnDataType::String), // Tag column
timestamp("ts", ColumnDataType::TimestampMillisecond), // timestamp
field("temperature", ColumnDataType::Float64), // Field
field("humidity", ColumnDataType::Float64), // Field
];
// Created real-time data
let sensor_data = vec![Row {
values: vec![
string_value("sensor_001".to_string()),
timestamp_millisecond_value(1234567890000),
f64_value(23.5),
f64_value(65.2),
],
}];
// Real-time data writing
let insert_request = RowInsertRequests {
inserts: vec![RowInsertRequest {
table_name: "sensor_readings".to_string(),
rows: Some(Rows { schema: sensor_schema, rows: sensor_data }),
}],
};
let start_time = std::time::Instant::now();
let affected_rows = database.insert(insert_request).await?;
let latency = start_time.elapsed();
println!("Real-time write successful: {} lines of data,delay: {:.1}ms",
affected_rows, latency.as_millis());
Ok(())
}Bulk Stream Insert API
Best for: ETL pipelines, historical imports, bulk log ingestion
Characteristics:
- Latency: 100–10,000 ms (batch-based)
- Throughput: >10K rows/sec
- Memory: Stable with backpressure
- Networking: Streamed writes over dedicated connections per table
Key Features:
- Parallel requests.
- Streamed Arrow Flight protocol.
- Zstd/LZ4 compression.
- Asynchronous, backpressure-aware submission.
Getting Started with Bulk Stream Insert
Core Concepts
- BulkInserter: Factory for table-specific stream writers.
- BulkStreamWriter: Dedicated writer tied to a specific table schema.
- Schema Binding: Each writer handles only one table.
- Async Submission: Multiple batches can be submitted in parallel.
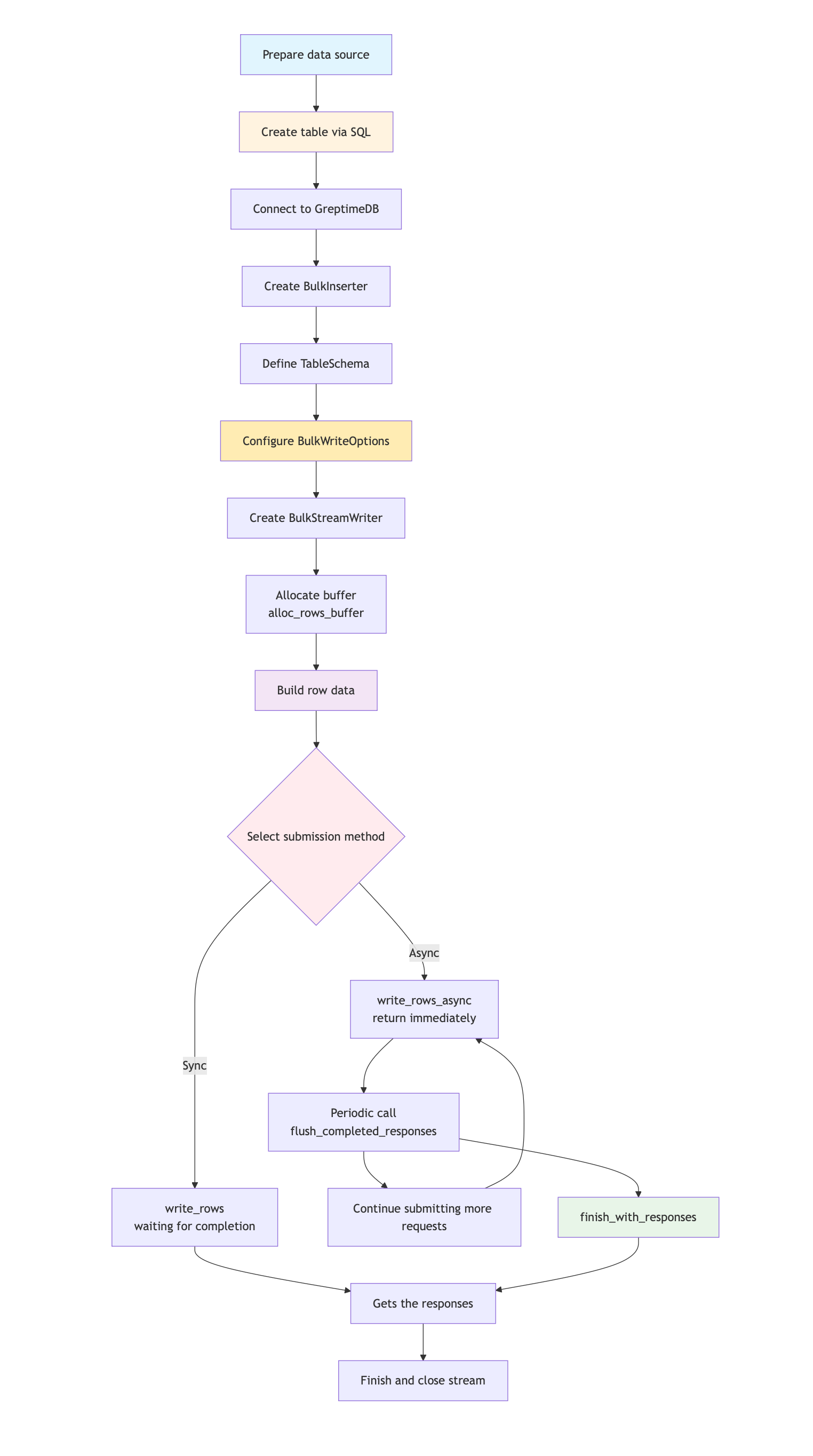
Workflow
- Pre-create table using SQL DDL.
- Initialize BulkInserter and BulkStreamWriter.
- Prepare batch data and submit asynchronously.
- Flush responses and manage resources. Workflow diagram
Key Components
BulkInserter & BulkStreamWriter
BulkInserter: ManagesBulkStreamWritercreationBulkStreamWriter: Handles batching, compression, async writes over persistent connections
BulkWriteOptions
Configure options, control compression, concurrency, and timeout settings:
rust
pub struct BulkWriteOptions {
pub compression: CompressionType, // LZ4 or Zstd
pub timeout: Duration,
pub parallelism: usize,
}Practical Usage
Basic workflow
1. Table Creation
Note: Unlike the regular write API, Bulk Stream Insert does not automatically create tables. Users must first create the table structure using SQL DDL, and automatic schema changes are not supported. It is also important to note that the Bulk API does not currently support primary key columns (Tags), and each row of data written must contain all columns. These limitations are expected to be gradually resolved in future versions, as the Bulk API is still in its early stages:
sql
CREATE TABLE sensor_data (
ts TIMESTAMP TIME INDEX,
sensor_id STRING,
temperature DOUBLE
)
ENGINE=mito
WITH(
append_mode = 'true',
skip_wal = 'true'
);2. Schema Binding
Note that it must match the table structure in the database exactly.
rust
let table_template = TableSchema::builder()
.name("sensor_data")
.add_timestamp("ts", ColumnDataType::TimestampMillisecond)
.add_field("sensor_id", ColumnDataType::String)
.add_field("temperature", ColumnDataType::Float64)
.build()
.unwrap();3. Creating Bulk Stream Writer
rust
let mut bulk_writer = bulk_inserter
.create_bulk_stream_writer(
&table_template,
Some(BulkWriteOptions::default()
.with_parallelism(8)
.with_compression(CompressionType::Zstd)
.with_timeout(Duration::from_secs(60))),
)
.await?;Three Insert Approaches
- Fast API: Best performance, positional values
- Safe API: Validates field names
- Indexed API: Uses index for balance of safety and speed
The following code shows three different implementations of the same data writing scenario:
rust
use greptimedb_ingester::{Row, Value, Result, BulkStreamWriter};
async fn demonstrate_three_approaches(bulk_writer: &mut BulkStreamWriter) -> Result<()> {
// Prepare sample data
let timestamp = 1234567890000i64;
let sensor_id = "sensor_001".to_string();
let temperature = 25.5f64;
// Create a buffer
let mut rows = bulk_writer.alloc_rows_buffer(10000, 1024)?;
// Option 1: Fast API - Optimal performance, requires ensuring that the field order is correct.
let row1 = Row::new().add_values(vec![
Value::TimestampMillisecond(timestamp),
Value::String(sensor_id.clone()),
Value::Float64(temperature),
]);
rows.add_row(row1)?;
// Option 2: Safe API - Field name verification to avoid incorrect field order
let row2 = bulk_writer.new_row()
.set("ts", Value::TimestampMillisecond(timestamp))?
.set("sensor_id", Value::String(sensor_id.clone()))?
.set("temperature", Value::Float64(temperature))?
.build()?;
rows.add_row(row2)?;
// Option 3: Index API - Balancing performance and safety by setting fields through indexes
let row3 = bulk_writer.new_row()
.set_by_index(0, Value::TimestampMillisecond(timestamp))? // index 0: ts
.set_by_index(1, Value::String(sensor_id))? // index 1: sensor_id
.set_by_index(2, Value::Float64(temperature))? // index 2: temperature
.build()?;
rows.add_row(row3)?;
let response = bulk_writer.write_rows(rows).await?;
println!("Wrote successfully: {} lines of data", response.affected_rows());
Ok(())
}Synchronous vs Asynchronous Writes
| Method | Calling Method | Usage Scenario | Pros | Cons |
|---|---|---|---|---|
write_rows() | Submit and wait for completion | Simple low-frequency | Simple, immediate feedback | Blocking, lower throughput |
write_rows_async() + flush_completed_responses() | Batch submission + regular refresh | High-frequency bulk | True parallelism, backpressure-safe | Requires response handling |
rust
// Synchronous submission - Simple scenario
let response = bulk_writer.write_rows(rows).await?;
println!("Synchronous writing: {} lines", response.affected_rows());
// Asynchronous submission - batch submission + periodic refresh
let mut batch_count = 0;
let batches: Vec<greptimedb_ingester::Rows> = vec![]; // Example: Pre-prepared batch data
for batch in batches {
bulk_writer.write_rows_async(batch).await?;
batch_count += 1;
Flush the completed response once every 100 batches submitted.
if batch_count % 100 == 0 {
let completed = bulk_writer.flush_completed_responses();
println!("Completed {} batches", completed.len());
}
}Buffering Strategy
The two parameters of alloc_rows_buffer(capacity, row_buffer_size) serve the following purposes:
capacity: The pre-allocated number of rows per column to avoid performance overhead caused by dynamic resizing.- Recommended value: Set based on the batch size, e.g., 1000–50000.
- Too small: Frequent resizing impacts performance.
- Too large: Occupies excessive memory.
row_buffer_size: Acts as a buffer during row-to-column transformation, optimizing the efficiency of this process.- Empirical value: 1024.
- Too small: Results in frequent row-to-column conversions.
- Too large: Wastes memory space.
Async Batch Submission Pattern
Bulk Stream Insert Asynchronous Commit
rust
use greptimedb_ingester::{Row, Value, Result};
async fn batch_async_submit(mut bulk_writer: greptimedb_ingester::BulkStreamWriter) -> Result<()> {
let batch_count = 1000;
let rows_per_batch = 1000;
let mut total_flushed_rows = 0usize;
// Phase 1: Rapid submission of all batches
for batch_id in 0..batch_count {
let mut rows = bulk_writer.alloc_rows_buffer(rows_per_batch, 1024)?;
// Fill data...
for i in 0..rows_per_batch {
let timestamp = 1234567890000 + ((batch_id * rows_per_batch + i) as i64 * 1000);
let sensor_id = format!("sensor_{:06}", (batch_id * rows_per_batch + i) % 1000);
let temperature = 18.0 + ((batch_id * rows_per_batch + i) as f64 * 0.03) % 25.0;
let row = Row::new().add_values(vec![
Value::TimestampMillisecond(timestamp),
Value::String(sensor_id),
Value::Float64(temperature),
]);
rows.add_row(row)?;
}
// Asynchronous submission, no waiting for response
let _request_id = bulk_writer.write_rows_async(rows).await?;
// Flush completed responses once every 100 batches to prevent memory accumulation.
if (batch_id + 1) % 100 == 0 {
let completed = bulk_writer.flush_completed_responses();
let flushed_rows: usize = completed.iter().map(|r| r.affected_rows()).sum();
total_flushed_rows += flushed_rows;
println!("Flushed {} completed responses, totaling {flushed_rows} rows of data.", completed.len());
}
}
println!("All batches have been submitted and are awaiting processing results...");
// Phase 2: Close connections and collect remaining responses
let remaining_responses = bulk_writer.finish_with_responses().await?;
let remaining_rows: usize = remaining_responses.iter().map(|r| r.affected_rows()).sum();
let total_rows = total_flushed_rows + remaining_rows;
println!("Bulk Stream Insert completed: {total_rows} lines of data");
println!("The following have been updated: {total_flushed_rows} lines,finally collected: {remaining_rows} 行");
println!("Successfully processed {batch_count} batches");
Ok(())
}Performance Optimization
Concurrency Tuning
rust
// Assume a single instance writing to a single table, CPU cores = 4
// Network-Bound: Bulk Stream Insert mainly waits for network transmission
let network_bound_options = BulkWriteOptions::default()
.with_parallelism(16); // Recommended: 8-16, to fully utilize network bandwidth
// CPU-Intensive: When heavy computation is required before data insertion
let cpu_intensive_options = BulkWriteOptions::default()
.with_parallelism(4); // Recommended: set to the number of CPU cores
// Mixed Workload: Adjust according to the actual bottleneck
let balanced_options = BulkWriteOptions::default()
.with_parallelism(8); // Balance between network and CPUCompression Choice
rust
// Zstd: Higher compression ratio, suitable for environments with limited network bandwidth; may consume more CPU
let zstd_options = BulkWriteOptions::default()
.with_compression(CompressionType::Zstd);
// Lz4: Faster compression speed, suitable for environments with limited CPU resources
let lz4_options = BulkWriteOptions::default()
.with_compression(CompressionType::Lz4);
// No Compression: Fastest speed, suitable for high-speed network environments
let no_compression_options = BulkWriteOptions::default()
.with_compression(CompressionType::None);Batch Size Tuning
rust
// Small batch: Lower latency, suitable for scenarios with high real-time requirements
let small_batch_rows = bulk_writer.alloc_rows_buffer(1_000, 512)?;
// Large batch: Higher throughput, suitable for batch processing scenarios
let large_batch_rows = bulk_writer.alloc_rows_buffer(100_000, 2048)?;Benchmarks
A benchmark tool is available in greptimedb-ingester-rust, simulating log workloads with 22 fields.
Table Schema
sql
CREATE TABLE IF NOT EXISTS `benchmark_logs` (
`ts` TIMESTAMP(3) NOT NULL,
`log_uid` STRING NULL,
`log_message` STRING NULL,
`log_level` STRING NULL,
`host_id` STRING NULL,
`host_name` STRING NULL,
`service_id` STRING NULL,
`service_name` STRING NULL,
`container_id` STRING NULL,
`container_name` STRING NULL,
`pod_id` STRING NULL,
`pod_name` STRING NULL,
`cluster_id` STRING NULL,
`cluster_name` STRING NULL,
`trace_id` STRING NULL,
`span_id` STRING NULL,
`user_id` STRING NULL,
`session_id` STRING NULL,
`request_id` STRING NULL,
`response_time_ms` BIGINT NULL,
`log_source` STRING NULL,
`version` STRING NULL,
TIME INDEX (`ts`)
)
ENGINE=mito
WITH(
append_mode = 'true',
skip_wal = 'true'
);Data Characteristics
Key Features: Large log_message Field
- Target Length: 1,500 characters (actual length ranges from 1,350 to 1,650 characters).
- Content Generation: Template-based system that produces different types of messages according to log level.
- Stack Trace: For ERROR level logs, there's a 70% probability of including 3–8 lines of Java stack trace information.
- Placeholder Replacement: Dynamically replaces variables such as user ID, IP address, timestamps, etc.
Field Cardinality / Dimension Distribution
High Cardinality Fields (Nearly Unique):
trace_id,span_id: Generated using64-bitrandom numberssession_id,request_id: Generated using64-bitrandom numberslog_uid: Ensured uniqueness based on timestamp + row index
Medium Cardinality Fields (About 100,000 Values):
host_id/host_name: id format ashost-{0-99999}service_id/service_name: id format asservice-{0-99999}container_id/container_name: id format ascontainer-{0-99999}pod_id/pod_name: id format aspod-{0-99999}cluster_id/cluster_name: id format ascluster-{0-99999}
Low-cardinality and other fields are omitted here.
Data Distribution Characteristics
- Log Level Distribution (Realistic Production Pattern):
INFO: 84%, normal operation messagesDEBUG: 10%, detailed diagnosis informationWARN: 5%, warning messagesERROR: 1%, error messages with stack trace
Run Benchmark Test
- Start GreptimeDB
- Create a table
- Sequentially start Bulk & Regular API Benchmarks
- Startup commands:
shell
# Bulk API Benchmark
cargo run --example bulk_api_log_benchmark --release
# Regular API Benchmark
cargo run --example regular_api_log_benchmark --release- My local test results are as follows:
| API Type | Throughput | Total Time | Avg. Latency | Improvement |
|---|---|---|---|---|
| Bulk API | 155,099 rows/s | 12.90s | N/A (async) | +48.8% |
| Regular API | 104,237 rows/s | 19.19s | 683.46ms | Baseline |
Bulk API Results
plain
=== GreptimeDB Bulk API Log Benchmark ===
Target rows: 2000000
Batch size: 100000
Parallelism: 8
→ Batch 1: 100000 rows processed (201010 rows/sec)
→ Batch 10: 1000000 rows processed (193897 rows/sec)
→ Batch 20: 2000000 rows processed (195556 rows/sec)
Final Results:
• Total rows: 2000000
• Total batches: 20
• Duration: 12.90s
• Throughput: 155090 rows/secRegular API Results
plain
=== GreptimeDB Regular API Log Benchmark ===
Target rows: 2000000
Batch size: 100000
→ Batch 1: 100000 rows processed, 100000 affected (125120 rows/sec, 641.73ms latency)
→ Batch 10: 100000 rows processed, 100000 affected (119781 rows/sec, 620.04ms latency)
→ Batch 20: 100000 rows processed, 100000 affected (104761 rows/sec, 775.90ms latency)
Final Results:
• Total rows: 2000000
• Total batches: 20
• Duration: 19.19s
• Throughput: 104232 rows/sec
• Average latency: 683.46msMore benchmark details here.
Summary
As shown in this log testing scenario:
Throughput: Bulk API (155,099 rows/s) is almost 50% faster than Regular API (104,237 rows/s). It’s worth noting that this test was conducted locally using the loopback interface, so network bandwidth pressure was not a consideration. Also, Regular API did not enable gRPC compression, whereas Bulk API used Arrow encoding with Lz4 compression. If you enable compression for the Regular API, throughput drops significantly due to the large data volume (those results aren’t listed here—feel free to try it out yourself if interested).
Regular API is more suitable for scenarios with smaller data per request, for example writing 200–500 rows at a time, and where low throughput is acceptable but low latency is preferred (manual testing is recommended).
Bulk API is more suitable for scenarios requiring higher throughput and can tolerate some latency—this may include the time needed to accumulate data on the client side before writing it to the database in bulk.
So how should you choose? Here are some reference scenarios below: 👇
When to Use Which API
| Use Case | Recommended API | Reason |
|---|---|---|
| Real-time alerting | Regular API | Immediate response needed |
| IoT sensors | Regular API | Small data, low-latency required |
| Interactive dashboards | Regular API | Responsive UX |
| ETL pipelines | Bulk API | High volume, delay-tolerant |
| Log collection and ingestion | Bulk API | Batch-friendly, high throughput |
| Historical import | Bulk API | One-off large ingestion |
When selecting a specific API, please make a comprehensive assessment based on factors such as data real-time requirements, system resource pressure, and network bandwidth.
The two write methods provided by GreptimeDB each have their own advantages in different scenarios. For developers, flexibly combining these writing capabilities allows you to better meet actual business needs and achieve goals for system scalability and high performance.




