
On this page
Today we are releasing GreptimeDB v1.0 GA.
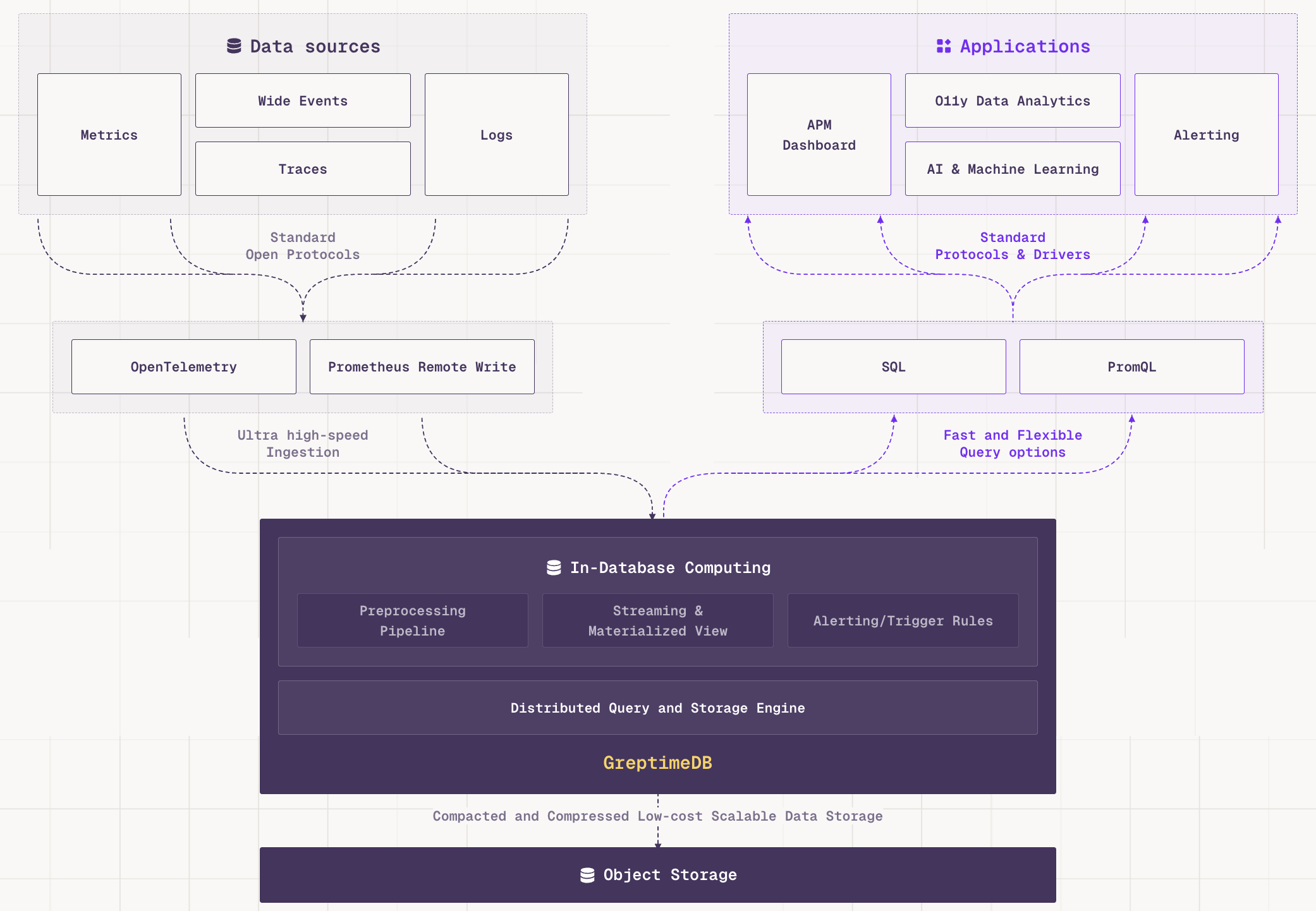
GreptimeDB is an open-source, cloud-native observability database that handles metrics, logs, and traces in one engine. Built on object storage with SQL and PromQL support, it can replace the Prometheus + Loki + Elasticsearch stack.
From Beta1 last November to GA today, we went through Beta2, RC1, and RC2. Over the past few months we have been doing one thing: turning a system with a clear direction but fast-moving internals into a stable release.
v1.0 is more of a dividing line. From here on, we need to operate as a long-term maintained infrastructure project.
A few things GreptimeDB has stuck with over the years:
- Unified processing of metrics, logs, and traces
- Fitting into existing ecosystems rather than asking users to rewrite their stack
- Prioritizing maintainability and sustainable evolution over feature count
By v1.0, these bets have been validated through multiple releases and real-world deployments.
Beta to GA
Looking back at the release line: Beta spread the capabilities, RC tightened things up.
In Beta we shipped BulkMemtable, global index rebuild, and batch Region migration. In RC the focus shifted to performance tuning, stability validation, compatibility fixes, and those small but production-critical details.
GA is where the two lines converge. The capabilities from Beta plus the stability and compatibility work from RC come together into a more complete release.
What changed in v1.0
Flat is now the default SST format
One of the most important changes in v1.0: Flat is now the default SST format.
This targets high-cardinality workloads. The original primary_key format encodes all tag columns into a single binary column, and the memtable allocates a separate buffer for each series. Once series count reaches the millions, memory overhead and query performance both degrade significantly. The Flat format splits tag columns back into individual Parquet columns and pairs with the new BulkMemtable, which drops the per-series buffer design. In TSBS benchmarks with 2 million series, write throughput improved roughly 4×, and some query latencies dropped by up to 10×. See this post for the full design and performance data.
Starting with v1.0, flush, compaction, and scan all go through the Flat path. The Flat scan path reads both flat and primary_key format data.
For existing users, the change is non-disruptive:
- Existing tables using
primary_keyformat continue to work - New tables default to Flat
- You can switch back to
primary_keyexplicitly
sql
ALTER TABLE my_table SET 'sst_format' = 'primary_key';When writing via HTTP, you can specify the format with a header:
x-greptime-hints: sst_format=primary_keyWrite path improvements
The write path saw a lot of work in v1.0.
For metrics, the Metric Engine now supports bulk inserts with pending rows batching and automatic Prometheus schema alignment. Prometheus remote write throughput has improved; a detailed benchmark report will follow separately.
For OTLP, we fixed two common production issues: trace ingestion now supports partial success, so partial errors no longer fail the entire batch. When trace ingestion encounters int-to-float type mismatches, schema adaptation happens automatically.
Query improvements
PromQL range functions got a rewritten execution path. Group accumulators for aggregate queries now support state wrappers. Window queries with LIMIT no longer perform unnecessary sorting. These changes show up in real query response times.
Built-in dashboard
This release adds built-in Perses dashboard support, updated to v0.12.0.
Once data is ingested, you can query and visualize directly in GreptimeDB without setting up a separate visualization tool. The latest version of GreptimeDB MCP Server also added support for creating Perses dashboards, so you can now build dashboards through LLM conversations.
PostgreSQL compatibility
v1.0 also includes a round of PostgreSQL protocol compatibility fixes: extended query optimization, ParameterDescription size limit handling, 8-bit int to smallint mapping, and format-related sync cleanup.
What v1.0 GA means for users
v1.0 GA does not mean everything is done. The architecture will keep evolving.
But the core direction has been validated from Beta through GA, and the main capabilities have reached the point of long-term maintenance. Users can evaluate and adopt GreptimeDB with more stable expectations.
Upgrading
For most users, the upgrade path to v1.0 is smooth. Pay attention to two breaking changes in the release notes.
1. New tables default to Flat SST format
Starting with v1.0, new tables use the Flat SST format by default:
- Existing tables using
primary_keyformat continue to work - You can explicitly specify or switch back to the old format
- Rename
region_engine.mito.default_experimental_flat_formattoregion_engine.mito.default_flat_formatin your config - Remove
region_engine.mito.parallel_scan_channel_sizeif previously set
2. Arrow IPC HTTP output changed from file to stream format
HTTP Arrow IPC output has switched from file to stream format. This affects custom clients or integrations that consume GreptimeDB's Arrow HTTP output directly. Verify that your reader supports Arrow IPC stream format before upgrading.
What comes next
The 2026 Roadmap lays out the direction after v1.0 GA:
- v1.1 (Q2): Remote Compaction/Indexing production-ready, Metric Engine optimization, Import/Export Tool v2
- v1.2 (Q3): Adaptive Resource Management phase 1 (fine-grained memory tracking, cost-based adaptive scheduling, zero-tuning adaptive spilling), Auto Rollup, Flow Engine enhancements
- v1.3 (Q4): Adaptive Resource Management phase 2, Pandas DataFrame SQL query, log context search, open table format compatibility (Iceberg/DeltaLake)
Adaptive Resource Management is the largest engineering effort this year, delivered in two phases. See the Roadmap tracking issue for details.
Development stats
From Beta1 to GA: 474 PRs merged, 27 contributors, 8 of whom contributed to GreptimeDB for the first time.
The v1.0.0 release alone includes 81 changes: 29 feature enhancements, 22 bug fixes, 7 refactors, 3 performance improvements, 3 documentation updates, 2 test enhancements, and 13 engineering/chore tasks.
First-time contributors in v1.0.0:
Thank you to all contributors.

Closing
Thank you to everyone who filed issues, submitted PRs, joined discussions, and ran GreptimeDB in real environments.




