On this page
Since v0.6, the distributed version of GreptimeDB has had the capability to migrate table partition (Region) data from one Datanode to another. In the previous article, we provided a detailed illustration of the specific technical details of implementing Region Migration.
This article will demonstrate how to use this feature in detail.
Prerequisites
Before starting, please ensure that the distributed cluster in your environment meets the following conditions; failing to meet any one of these will result in the failure of Region Migration.
Use of Remote WAL
Use of shared storage (e.g., AWS S3)
We will use a table named "monitor" as an example and demonstrate how to migrate a table partition (Region) to another Datanode node.
sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu DOUBLE DEFAULT 0,
memory DOUBLE,
PRIMARY KEY(host));Write some data into the table:
sql
INSERT INTO monitor
VALUES
("127.0.0.1", 1702433141000, 0.5, 0.2),
("127.0.0.2", 1702433141000, 0.3, 0.1),
("127.0.0.1", 1702433146000, 0.3, 0.2),
("127.0.0.2", 1702433146000, 0.2, 0.4),
("127.0.0.1", 1702433151000, 0.4, 0.3),
("127.0.0.2", 1702433151000, 0.2, 0.4);Querying Table Partition (Region) Distribution
First, we need to inquire about the distribution of table partitions (Regions), that is, to find out on which Datanode nodes the Regions of the table are located.
sql
select
b.peer_id as datanode_id,
a.greptime_partition_id as region_id
from
information_schema.partitions a
left join
information_schema.greptime_region_peers b
on a.greptime_partition_id = b.region_id
where a.table_name='monitor'
order by datanode_id asc;The query results indicate that the table comprises one Region, identified by Region ID 4398046511104 and hosted on the node with Datanode ID 1.
sql
+-------------+---------------+
| datanode_id | region_id |
+-------------+---------------+
| 1 | 4398046511104 |
+-------------+---------------+
1 row in set (0.01 sec)Performing Region Migration
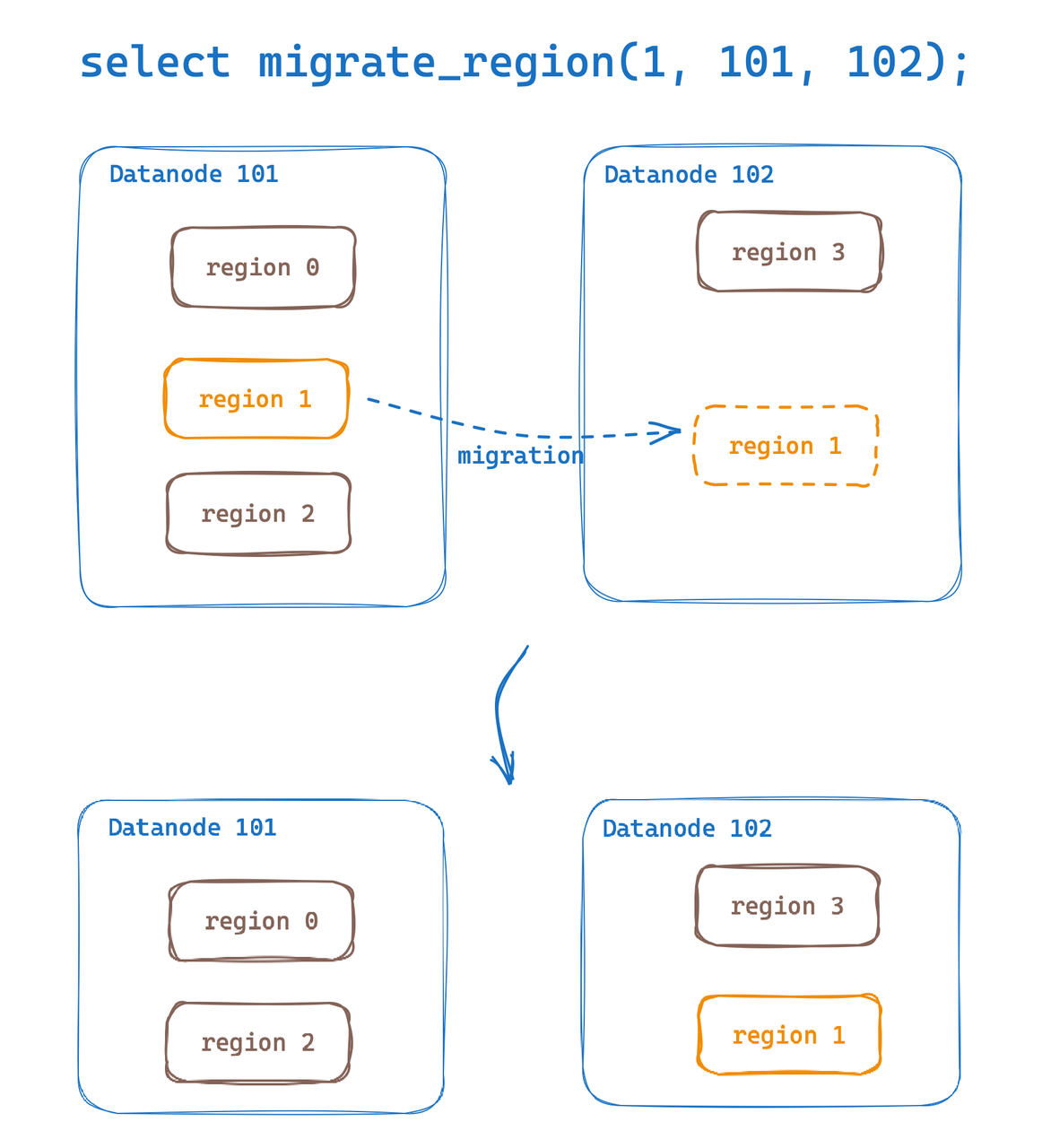
We can migrate the table's Region to another node (the demonstration cluster includes 3 Datanode nodes with IDs 0, 1, and 2).
As shown below, the Region with ID 4398046511104 will be migrated to the node with Datanode ID 2.
The fourth parameter is optional and sets the Replay Timeout (secs) for the region migration, with a default value of 10 seconds. If the network bandwidth between Kafka and the Datanode is insufficient, potentially delaying the migration process, adjusting this parameter upwards may be necessary.
sql
select migrate_region(4398046511104, 1, 2, 60);sql
+------------------------------------------------------------------+
| migrate_region(Int64(4398046511104),Int64(1),Int64(2),Int64(60)) |
+------------------------------------------------------------------+
| 0f65f485-2790-4bf3-8b71-74f73ef15457 |
+------------------------------------------------------------------+
1 row in set (0.00 sec)After initiating the migration, a Procedure ID corresponding to the migration is returned. This ID can be used to inquire about the status of migration.
Querying Migration Status
sql
select procedure_state('0f65f485-2790-4bf3-8b71-74f73ef15457');sql
+---------------------------------------------------------------+
| procedure_state(Utf8("0f65f485-2790-4bf3-8b71-74f73ef15457")) |
+---------------------------------------------------------------+
| {"status":"Done"} |
+---------------------------------------------------------------+
1 row in set (0.00 sec)When the query returns a status of "Done," it indicates that the Procedure has been successfully completed.
Querying Post-Migration Table Region Information
Upon querying the Table Region information again, it can be observed that the Region has been migrated to the Datanode with ID 2.
sql
select * from information_schema.greptime_region_peers;sql
+---------------+---------+--------------------------------------------------------------+-----------+--------+--------------+
| region_id | peer_id | peer_addr | is_leader | status | down_seconds |
+---------------+---------+--------------------------------------------------------------+-----------+--------+--------------+
| 4398046511104 | 2 | greptimedb-datanode-2.greptimedb-datanode.my-greptimedb:4001 | Yes | ALIVE | NULL |
+---------------+---------+--------------------------------------------------------------+-----------+--------+--------------+
1 row in set (0.02 sec)Learn More
To learn more about the distributed version of GreptimeDB, we invite you to read related articles for a deeper understanding of GreptimeDB's distributed capabilities and to maximize its value.
This article is designed to help you fully recognize and utilize the powerful features of GreptimeDB's distributed version, bringing greater convenience and benefits to data management and distributed computing. If you encounter any questions while using it, we encourage you to consult the relevant documentation for a comprehensive understanding of the system.
About Greptime
Greptime offers industry-leading time series database products and solutions to empower IoT and Observability scenarios, enabling enterprises to uncover valuable insights from their data with less time, complexity, and cost.
GreptimeDB is an open-source, high-performance time-series database offering unified storage and analysis for metrics, logs, and events. Try it out instantly with GreptimeCloud, a fully-managed DBaaS solution—no deployment needed!
The Edge-Cloud Integrated Solution combines multimodal edge databases with cloud-based GreptimeDB to optimize IoT edge scenarios, cutting costs while boosting data performance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected.




